【YOLO】目标识别模型的导出和opencv部署(三)_opencv yolov5-程序员宅基地
技术标签: YOLO python dnn # Python onnx opencv
0 前期教程
1 什么是模型部署
前期教程当中,介绍了yolov5环境的搭建以及如何利用yolov5进行模型训练和测试,虽然能够实现图片或视频的目标识别,但都是基于pytorch这个深度学习框架来实现的。仅仅是为了使用训练好的模型,就需要附加一个巨大的框架,这样程序会显得很臃肿,不够优雅。因此,摆脱对深度学习框架的依赖,是非常有必要的。此即深度学习模型的部署。
2 怎么部署
这里使用的是opencv的dnn模块,可以实现读取并使用深度学习模型。但是,这个模块不支持pytorch模型,即训练好的pt格式的文件,因此,使用该模型时,还需要先将pt文件转换为opencv能够读取的模型格式,即onnx。
模型格式的转换使用的是yolov5自带的export.py文件,它提供了多种常见深度学习框架对应的文件格式。老规矩,使用前先看文件开头的注释:
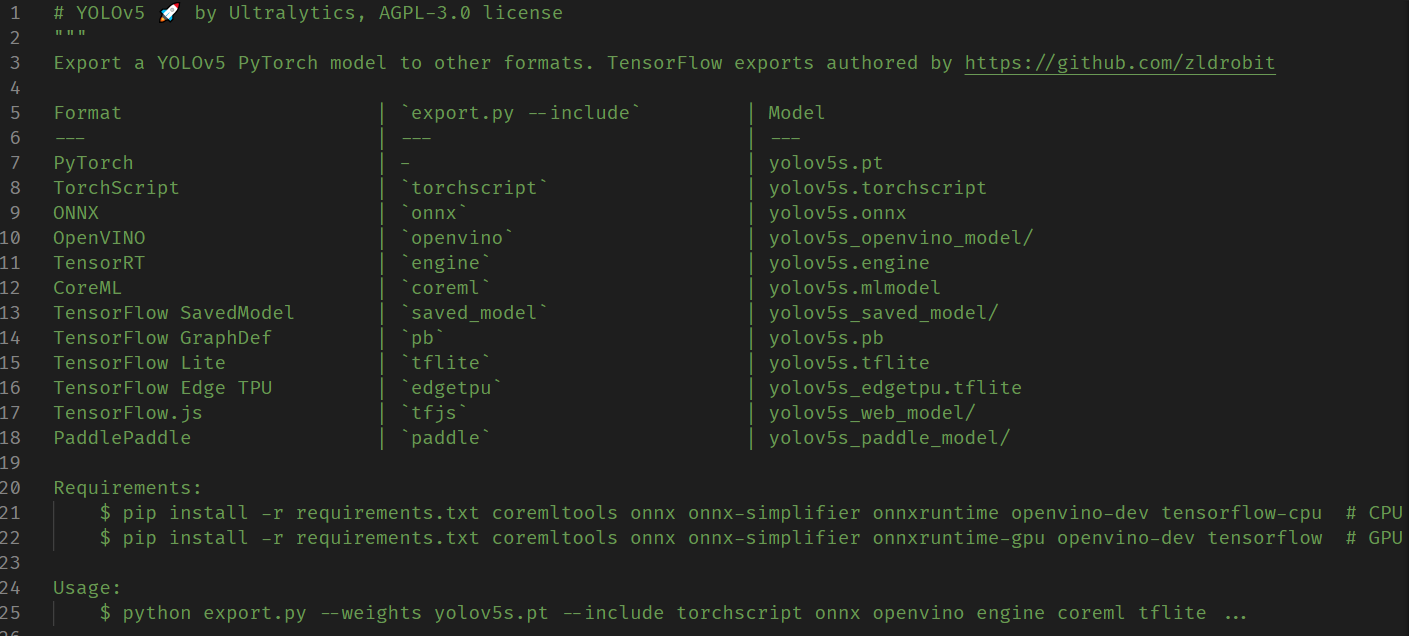
我们需要的是onnx格式,因此在运行前先安装onnx:
pip install onnx
然后运行export.py文件:
python export.py --weights 'C:\Users\Zeoy\Desktop\Code\Python\yolov5-master\runs\train\exp19\weights\best.pt' --include onnx
生成的onnx文件也在原best.pt所在文件夹下。
转换完毕,接下来就是使用,运行如下所示代码:
import cv2
import numpy as np
class Onnx_clf:
def __init__(self, onnx:str='Material/best.onnx', img_size=640, classlist:list=['bottle']) -> None:
''' @func: 读取onnx模型,并进行目标识别
@para onnx:模型路径
img_size:输出图片大小,和模型直接相关
classlist:类别列表
@return: None
'''
self.net = cv2.dnn.readNet(onnx) # 读取模型
self.img_size = img_size # 输出图片尺寸大小
self.classlist = classlist # 读取类别列表
def img_identify(self, img, ifshow=True) -> np.ndarray:
''' @func: 图片识别
@para img: 图片路径或者图片数组
ifshow: 是否显示图片
@return: 图片数组
'''
if type(img) == str: src = cv2.imread(img)
else: src = img
height, width, _ = src.shape #注意输出的尺寸是先高后宽
_max = max(width, height)
resized = np.zeros((_max, _max, 3), np.uint8)
resized[0:height, 0:width] = src # 将图片转换成正方形,防止后续图片预处理(缩放)失真
# 图像预处理函数,缩放裁剪,交换通道 img scale out_size swapRB
blob = cv2.dnn.blobFromImage(resized, 1/255.0, (self.img_size, self.img_size), swapRB=True)
prop = _max / self.img_size # 计算缩放比例
dst = cv2.resize(src, (round(width/prop), round(height/prop)))
# print(prop) # 注意,这里不能取整,而是需要取小数,否则后面绘制框的时候会出现偏差
self.net.setInput(blob) # 将图片输入到模型
out = self.net.forward() # 模型输出
# print(out.shape)
out = np.array(out[0])
out = out[out[:, 4] >= 0.5] # 利用numpy的花式索引,速度更快, 过滤置信度低的目标
boxes = out[:, :4]
confidences = out[:, 4]
class_ids = np.argmax(out[:, 5:], axis=1)
class_scores = np.max(out[:, 5:], axis=1)
# out2 = out[0][out[0][:][4] > 0.5]
# for i in out[0]: # 遍历每一个框
# class_max_score = max(i[5:])
# if i[4] < 0.5 or class_max_score < 0.25: # 过滤置信度低的目标
# continue
# boxes.append(i[:4]) # 获取目标框: x,y,w,h (x,y为中心点坐标)
# confidences.append(i[4]) # 获取置信度
# class_ids.append(np.argmax(i[5:])) # 获取类别id
# class_scores.append(class_max_score) # 获取类别置信度
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.25, 0.45) # 非极大值抑制, 获取的是索引
# print(indexes)
iffall = True if len(indexes)!=0 else False
# print(iffall)
for i in indexes: # 遍历每一个目标, 绘制目标框
box = boxes[i]
class_id = class_ids[i]
score = round(class_scores[i], 2)
x1 = round((box[0] - 0.5*box[2])*prop)
y1 = round((box[1] - 0.5*box[3])*prop)
x2 = round((box[0] + 0.5*box[2])*prop)
y2 = round((box[1] + 0.5*box[3])*prop)
# print(x1, y1, x2, y2)
self.drawtext(src,(x1, y1), (x2, y2), self.classlist[class_id]+' '+str(score))
dst = cv2.resize(src, (round(width/prop), round(height/prop)))
if ifshow:
cv2.imshow('result', dst)
cv2.waitKey(0)
return dst, iffall
def video_identify(self, video_path:str) -> None:
''' @func: 视频识别
@para video_path: 视频路径
@return: None
'''
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
# print(fps)
while cap.isOpened():
ret, frame = cap.read()
#键盘输入空格暂停,输入q退出
key = cv2.waitKey(1) & 0xff
if key == ord(" "): cv2.waitKey(0)
if key == ord("q"): break
if not ret: break
img, res = self.img_identify(frame, False)
cv2.imshow('result', img)
print(res)
if cv2.waitKey(int(1000/fps)) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
@staticmethod
def drawtext(image, pt1, pt2, text):
''' @func: 根据给出的坐标和文本,在图片上进行绘制
@para image: 图片数组; pt1: 左上角坐标; pt2: 右下角坐标; text: 矩形框上显示的文本,即类别信息
@return: None
'''
fontFace = cv2.FONT_HERSHEY_COMPLEX_SMALL # 字体
# fontFace = cv2.FONT_HERSHEY_COMPLEX # 字体
fontScale = 1.5 # 字体大小
line_thickness = 3 # 线条粗细
font_thickness = 2 # 文字笔画粗细
line_back_color = (0, 0, 255) # 线条和文字背景颜色:红色
font_color = (255, 255, 255) # 文字颜色:白色
# 绘制矩形框
cv2.rectangle(image, pt1, pt2, color=line_back_color, thickness=line_thickness)
# 计算文本的宽高: retval:文本的宽高; baseLine:基线与最低点之间的距离(本例未使用)
retval, baseLine = cv2.getTextSize(text,fontFace=fontFace,fontScale=fontScale, thickness=font_thickness)
# 计算覆盖文本的矩形框坐标
topleft = (pt1[0], pt1[1] - retval[1]) # 基线与目标框上边缘重合(不考虑基线以下的部分)
bottomright = (topleft[0] + retval[0], topleft[1] + retval[1])
cv2.rectangle(image, topleft, bottomright, thickness=-1, color=line_back_color) # 绘制矩形框(填充)
# 绘制文本
cv2.putText(image, text, pt1, fontScale=fontScale,fontFace=fontFace, color=font_color, thickness=font_thickness)
if __name__ == '__main__':
clf = Onnx_clf()
import tkinter as tk
from tkinter.filedialog import askopenfilename
tk.Tk().withdraw() # 隐藏主窗口, 必须要用,否则会有一个小窗口
source = askopenfilename(title="打开保存的图片或视频")
# source = r'C:\Users\Zeoy\Desktop\YOLOData\data\IMG_568.jpg'
if source.endswith('.jpg') or source.endswith('.png') or source.endswith('.bmp'):
res, out = clf.img_identify(source, False)
print(out)
cv2.imshow('result', res)
cv2.waitKey(0)
elif source.endswith('.mp4') or source.endswith('.avi'):
print('视频识别中...按q退出')
clf.video_identify(source)
else:
print('不支持的文件格式')
关于这个代码流程的一些解释:
-
首先是调用
readNet函数读取onnx模型文件 -
然后对输入图片进行预处理。具体包括:首先需要用numpy将图片变成正方形(因为模型训练时用的就是正方形图片),不是直接拉伸,而是对短边进行填充值为0的像素,然后再调用
blobFromImage函数对得到的正方形图片进行预处理,包括像素值归一化处理,设置输出图像大小,将颜色空间转换为RGB等,具体参数可以参考这篇博客。注意,这里的输出图像大小要和训练时选择的img-size参数保持一致,默认是640,同时要记录一下正方形图片相对于输出图片大小的缩放比例,即正方形边长 / 640,是一个浮点数。 -
接下来就是图片的输入和输出,
setInput函数输入预处理好的图片块,然后调用forward函数得到模型输出,这些模型输出即是圈出的目标对应的方框。 -
上面得到的方框数量有2w多个,但并不是所有的都是目标,需要根据置信度进行选择,这里用的是numpy的花式索引,速度比循环操作大大加快。然后调用
NMSBoxes非极大值抑制,得到确定的目标,然后再循环进行画框输出即可。 -
具体内容就是读代码和注释即可理解。
智能推荐
【资料贴】64份数字化转型案例+方法论+报告 by彭文华-程序员宅基地
文章浏览阅读583次。这是彭文华的第174篇原创群里之前聊数字化转型的时候,得出一个结论:甭管你概念解释的多么好,道理讲的多么深,到最后还得看落地,落地就是看案例。是骡子是马,你得拉出来溜溜才知道。那有啥可说的..._高校数字化优秀案例巡展
微信小程序社区论坛源码_微信小程序源码论坛-程序员宅基地
文章浏览阅读2.8k次。简介:使用方法:后端搭建wordpress网站,推荐使用nginx1.18+php7.3+mysql5.6在wordpress插件市场搜索“REST API TO MiniProgram”安装并启用微慕小程序开源版插件设置wordpress固定连接及伪静态规则,推荐使用/%post_id%.html在浏览器输入https://xxx.com/wp-json/wp/v2/posts 或在浏览器输入https://xxx.com/wp-json/wp/v2 如果有数据输出则说明设置没有问题,如果出现_微信小程序源码论坛
软考高级架构师——5、系统规划分析与设计方法_软考高级系统分析-程序员宅基地
文章浏览阅读785次。问题分析在问题定义上达成共识理解问题的本质确定项目干系人和用户定义系统的边界确定系统实现的约束问题定义包括目标、功能需求和非功能需求三个方面。目标是指构建系统的原因,它是最高层次的用户需求,是业务上的需要功能需求功能需求是用来指明系统必须做的事情,只有这些行为的存在,才有系统存在的价值。非功能需求(1)观感需求(2)易用性需求(3)性能需求(4)可操作性需求(5)可维护性和可移植性需求(6)安全性需求(7)文化和政策需求( 8)法律需求。_软考高级系统分析
STM32F407VET6 FLASH读写 HAL库_stm32f407vet6flash分区-程序员宅基地
文章浏览阅读345次。STM32F103C8T6的flash按页擦除,而STM32F407VET6的flash是按扇区擦除的。每次操作的步骤为:对flash解锁、擦除、写入、上锁。文章为新手个人记录学习。_stm32f407vet6flash分区
C语言基本语法——循环篇(三种常见的循环)_c语言循环-程序员宅基地
文章浏览阅读8.8k次,点赞20次,收藏52次。对于新手小白来说,他们会困惑于循环是什么?循环可以用来做什么,C语言中有哪些循环,这些循环又该怎么使用呢?因此,本文总结了C语言中常见的循环类型,专门为小白解决循环这个难题。_c语言循环
Unity 特效 之 武器拖尾效果_unity拖尾折痕-程序员宅基地
文章浏览阅读1.3k次。Pocket RPG Weapon Trails 武器拖尾效果Asset Store地址..._unity拖尾折痕
随便推点
小样本语义分割论文及开源代码集合_小样本分割pgnet开源代码-程序员宅基地
文章浏览阅读2.6k次,点赞11次,收藏55次。主要是自然图像上的小样本分割,医学图像上的将另开一帖。本文持续更新中!One-Shot Learning for Semantic Segmentation(BMVC2017)开源代码CANet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning(CVPR2019)开源代码Pyramid Graph Networks with Connection Atte_小样本分割pgnet开源代码
微同城生活源码系统:专业搭建本地生活服务平台 附带完整的安装部署教程_本地生活平台源码-程序员宅基地
文章浏览阅读937次,点赞5次,收藏10次。微同城生活源码系统还支持实时的服务评价功能,用户在享受完服务后可以立即对服务进行评价和打分,为其他用户提供了参考依据。微同城生活源码系统涵盖了本地生活的方方面面,包括餐饮、购物、娱乐、家政服务等,满足了用户对于一站式生活服务的需求。微同城生活源码系统的后台管理功能强大,支持多账号管理、权限分配等功能,方便商家进行后台操作。基于大数据分析,微同城生活源码系统可以为用户提供个性化的推荐服务,根据用户的浏览和预订记录,推荐符合用户需求的商家和服务,提高用户的满意度。用户只需填写相关信息,即可完成预订,方便快捷。_本地生活平台源码
网络相关故障及处理方法_网口tx rx灯亮 rap失败-程序员宅基地
文章浏览阅读459次。常见故障:服务器连接上网线后物理网口的指示灯亮--------------------------网线: 未插牢,破损,交换机:未开机,网口故障服务器:未开机,网口故障操作系统: 未安装网卡驱动linux中网卡未inactive状态网卡做绑定,但配置错误或配置未激活直连服务器网口测试无法ping通------------------------------------网线,交换机..._网口tx rx灯亮 rap失败
管理系统---Django框架创建与完整实现过程详释_django开发的管理系统实例-程序员宅基地
文章浏览阅读3.8k次。使用Django开发一个管理系统,实现数据的增删改查操作,以及数据的可视化展示_django开发的管理系统实例
聊一聊基于激光雷达的车道线检测该怎么做-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。作者|Been 编辑|汽车人原文链接:https://zhuanlan.zhihu.com/p/388929795点击下方卡片,关注“自动驾驶之心”公众号ADAS巨卷干货,即可获取后台回复【车道线综述】获取基于检测、分割、分类、曲线拟合等近几十篇学习论文!为什么要用激光雷达:1.解决有阳光情况树荫下光照被碎片化带来的车道线图像检测问题2.解决涉水路面的车道线图像检测问题3.低照度环境下..._激光雷达道路标记线检测
仿真毕设 基于单片机的自动浇花系统-程序员宅基地
文章浏览阅读27次。# 1 简介Hi,大家好,今天向大家介绍一个学长做的单片机项目基于单片机的自动浇花系统大家可用于 课程设计 或 毕业设计 项目分享:https://gitee.com/feifei1122/simulation-project现在生活中,随着人们生活水平的提高,人们对花卉、树木等绿色植物的喜爱和种植越来越多,在家里养盆花能够陶冶情操,使生活多姿多彩。对花卉的浇灌、施肥等管理工作都需要人们来定期完成,但是由于现代生活节奏的加快,生活压力增大,使人们没有时间来照看自己家的花卉,人们往往忙于工作而忘记或者由