Kaggle共享单车需求项目详解_kaggle共享单车项目-程序员宅基地
技术标签: 数据分析 随机森林 sklearn机器学习 线性回归 数据可视化
Kaggle共享单车需求项目详解
1.查看数据
导入库
%matplotlib inline
import numpy as np
import pandas as pd
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='whitegrid' , palette='tab10')
导入数据
# 导入训练数据
train=pd.read_csv('E:/PythonData/Kaggle_Data/train.csv')
查看数据
train.head()

查看数据结构
train.shape
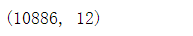
# 查看训练集是否有缺失值
train.info()
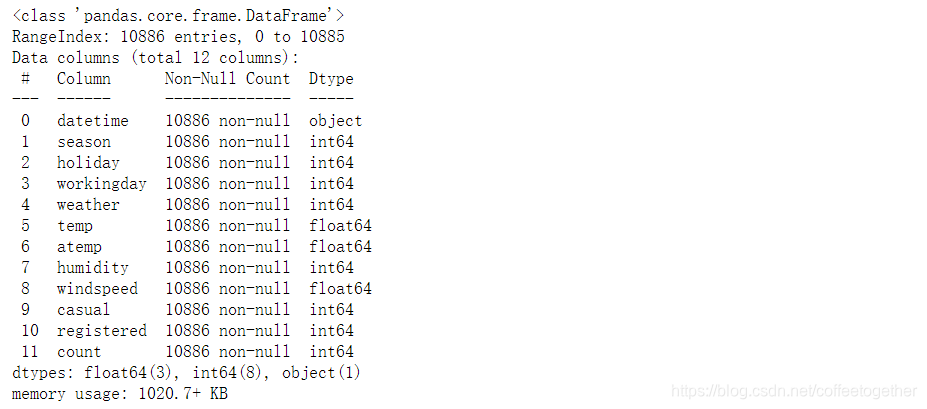
分析:由上述信息可知,训练集数据不存在缺失值。
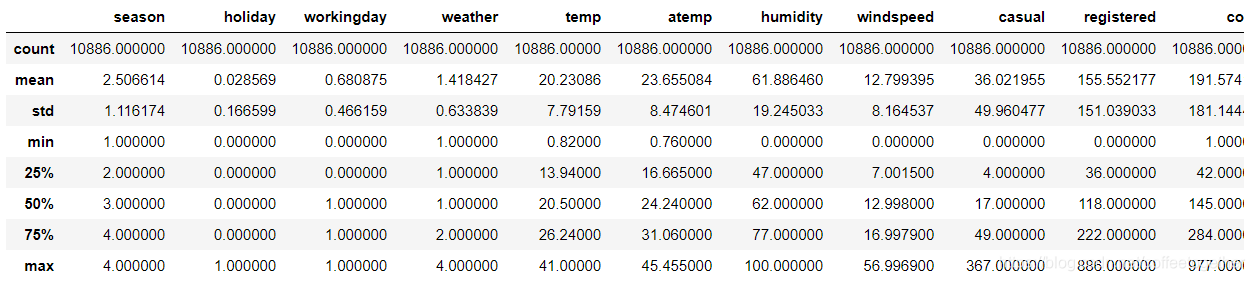
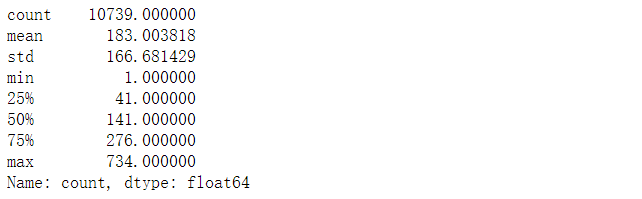
查看数据统计性信息
#观察训练集数据描述统计
train.describe()
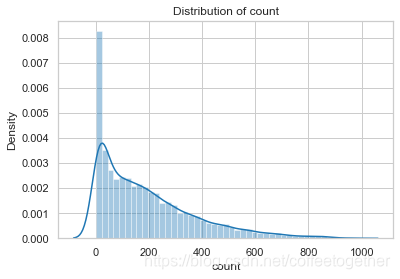
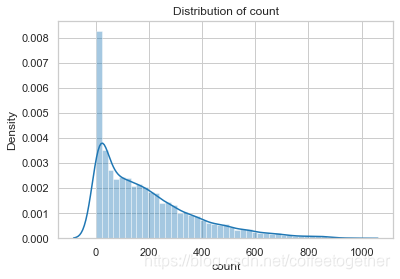
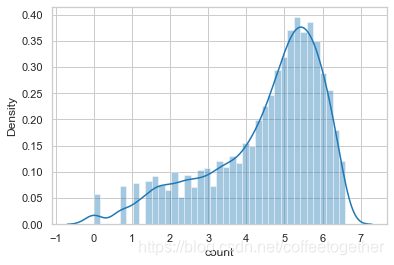
查看租赁数量分布图
# 绘制租赁额分布图
sns.distplot(train['count'])
# 添加标注
plt.title('Distribution of count')
plt.show()
2.数据预处理
# 去除与租赁租赁数量平均值相差3个标准差的租赁数据
train_WithoutOutliers = train[np.abs(train['count']-
train['count'].mean())<=(3*train['count'].std())]
train_WithoutOutliers .shape
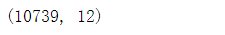
print('一共去除了%s条数据'%(10886-10739))
一共去除了147条数据
# 去除3个标准差的数据的统计性信息
train_WithoutOutliers['count'] .describe()
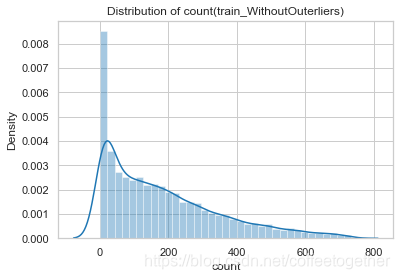
对比去除3个标准差数据前后的租赁总数量分布图
# 查看去除后数据的count的分布于未处理的数据、
sns.distplot(train['count'])
plt.title('Distribution of count')
plt.show()
sns.distplot(train_WithoutOutliers['count'])
plt.title('Distribution of count(train_WithoutOuterliers)')
plt.show()
将数据转换成对数数值
# 由于数据波动较大,因此通过对数据count进行转换成其对数形式
yLabels=train_WithoutOutliers['count']
yLabels_log=np.log(yLabels)
sns.distplot(yLabels_log)
导入测试集数据
test=pd.read_csv('E:/PythonData/Kaggle_Data/test.csv')
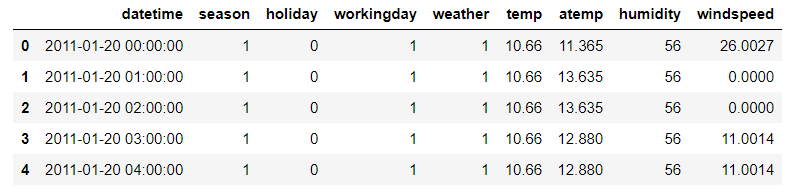
查看数据
test.head()
test.info()

合并数据集
Bike_data=pd.concat([train_WithoutOutliers,test],ignore_index=True)
Bike_data.head()

Bike_data.tail()

查看合并后数据结构
# 查看数据结构
Bike_data.shape

转换数据类型
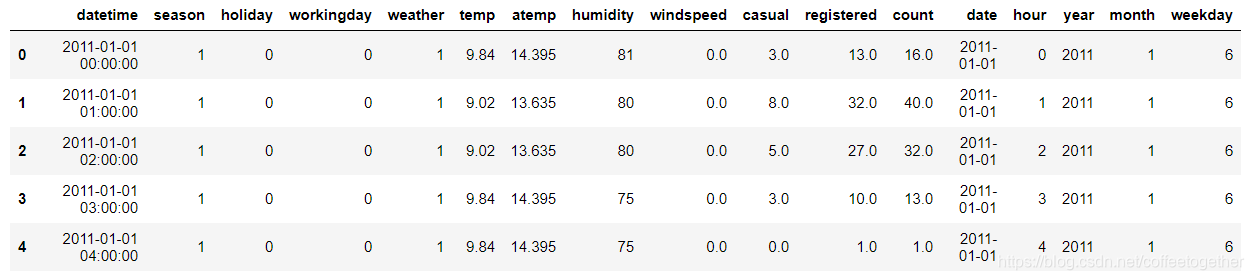
将日期分割成日期,时段,年,月,星期
# 对日期进行处理,转换成日期,时段,年份,月份,星期
Bike_data['date']=Bike_data.datetime.apply( lambda c : c.split( )[0])
Bike_data['hour']=Bike_data.datetime.apply( lambda c : c.split( )[1].split(':')[0]).astype('int')
Bike_data['year']=Bike_data.datetime.apply( lambda c : c.split( )[0].split('-')[0]).astype('int')
Bike_data['month']=Bike_data.datetime.apply( lambda c : c.split( )[0].split('-')[1]).astype('int')
Bike_data['weekday']=Bike_data.date.apply( lambda c : datetime.strptime(c,'%Y-%m-%d').isoweekday())
Bike_data.head()
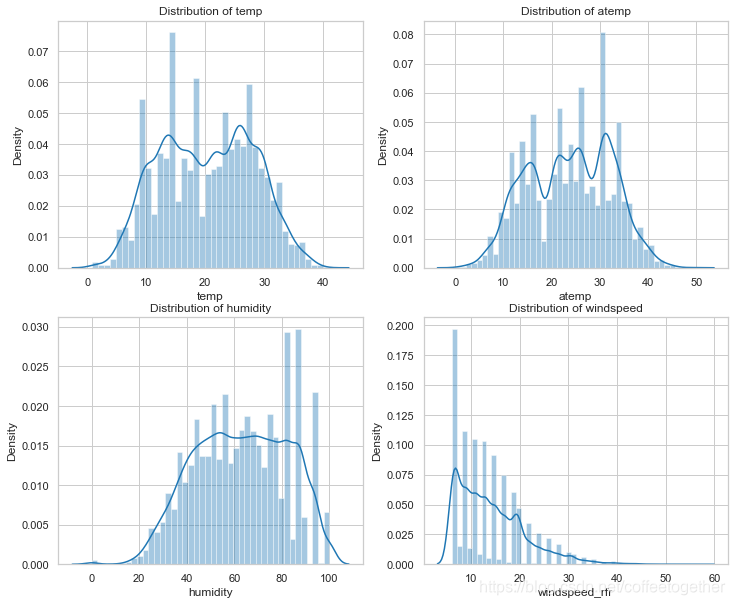
查看数值型特征分布情况
# 查看temp(温度),atemp(体感温度),humidity(湿度)、windspeed(风速)等数值型数据的分布情况
fig, axes = plt.subplots(2, 2)
fig.set_size_inches(12,10)
sns.distplot(Bike_data['temp'],ax=axes[0,0])
sns.distplot(Bike_data['atemp'],ax=axes[0,1])
sns.distplot(Bike_data['humidity'],ax=axes[1,0])
sns.distplot(Bike_data['windspeed'],ax=axes[1,1])
axes[0,0].set(title='Distribution of temp',)
axes[0,1].set(title='Distribution of atemp')
axes[1,0].set(title='Distribution of humidity')
axes[1,1].set(title='Distribution of windspeed')
plt.show()
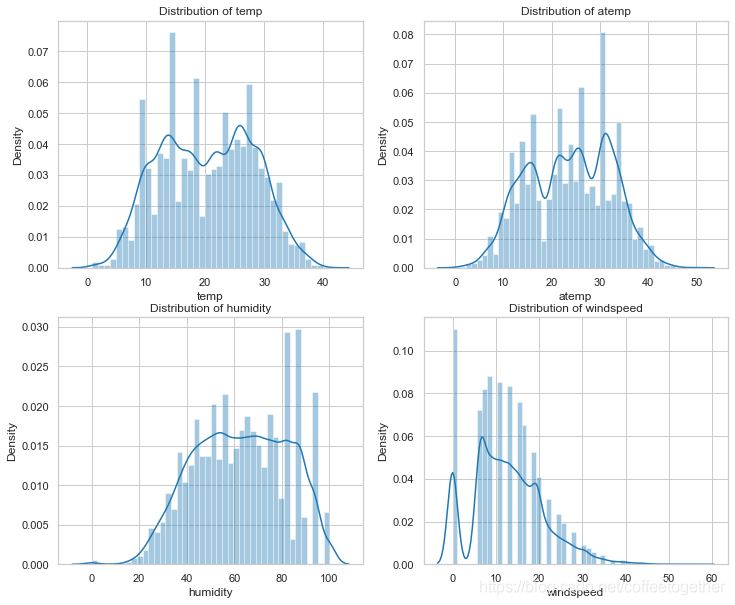
分析:查看上图发现,风速为0的数据居多。明显属于非正常数据
# 查看风速非0的数据的风速统计性信息描述
Bike_data[Bike_data['windspeed']!=0]['windspeed'].describe()

使用随机森林模型填充风速为0的数据
# 使用随机森林填充风速
from sklearn.ensemble import RandomForestRegressor
Bike_data["windspeed_rfr"]=Bike_data["windspeed"]
# 将数据分成风速等于0和不等于两部分
dataWind0 = Bike_data[Bike_data["windspeed_rfr"]==0]
dataWindNot0 = Bike_data[Bike_data["windspeed_rfr"]!=0]
#选定模型
rfModel_wind = RandomForestRegressor(n_estimators=1000,random_state=42)
# 选定特征值
windColumns = ["season","weather","humidity","month","temp","year","atemp"]
# 将风速不等于0的数据作为训练集,fit到RandomForestRegressor之中
rfModel_wind.fit(dataWindNot0[windColumns], dataWindNot0["windspeed_rfr"])
#通过训练好的模型预测风速
wind0Values = rfModel_wind.predict(X= dataWind0[windColumns])
#将预测的风速填充到风速为零的数据中
dataWind0.loc[:,"windspeed_rfr"] = wind0Values
#连接两部分数据
Bike_data = dataWindNot0.append(dataWind0)
Bike_data.reset_index(inplace=True)
Bike_data.drop('index',inplace=True,axis=1)
填充好再画图观察一下这四个特征值的密度分布
fig, axes = plt.subplots(2, 2)
fig.set_size_inches(12,10)
sns.distplot(Bike_data['temp'],ax=axes[0,0])
sns.distplot(Bike_data['atemp'],ax=axes[0,1])
sns.distplot(Bike_data['humidity'],ax=axes[1,0])
sns.distplot(Bike_data['windspeed_rfr'],ax=axes[1,1])
axes[0,0].set(title='Distribution of temp',)
axes[0,1].set(title='Distribution of atemp')
axes[1,0].set(title='Distribution of humidity')
axes[1,1].set(title='Distribution of windspeed')
plt.show()
3.分析数据
查看其他数值型特征值与临时和会员租赁总数的关系
# 查看临时租赁和会员租赁以及租赁总数与其他特征数值的关系
sns.pairplot(Bike_data ,x_vars=['holiday','workingday','weather','season',
'weekday','hour','windspeed_rfr','humidity','temp','atemp'] ,
y_vars=['casual','registered','count'] , plot_kws={'alpha': 0.1})
plt.show()
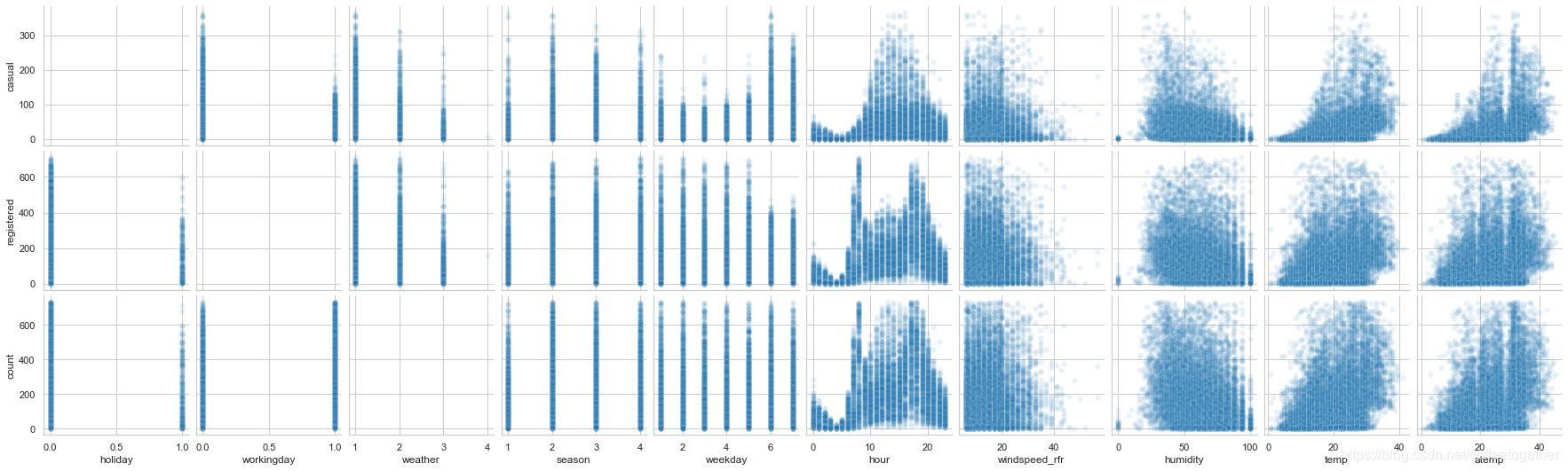
分析:
1.会员在工作日出行多,节假日出行少,临时用户则相反;
2.一季度出行人数总体偏少;
3.租赁数量随天气等级上升而减少;
4.小时数对租赁情况影响明显,会员呈现两个高峰,非会员呈现一个正态分布;
5.租赁数量随风速增大而减少;
6.温度、湿度对非会员影响比较大,对会员影响较小。
创建相关性矩阵
#创建相关性矩阵
corrDf = Bike_data.corr()
#ascending=False表示按降序排列
corrDf['count'].sort_values(ascending =False)

分析:
可以看出特征值对租赁数量的影响力度为,时段>温度>湿度>年份>月份>季节>天气等级>风速>星期几>是否工作日>是否假日,接下来再看一下共享单车整体使用情况。
3.1 时段对租赁数量的影响
# 时段对租赁数量的影响
# 查看工作日与非工作日每小时的临时租赁数量,会员租赁数量和总数量的平均值
workingday_df=Bike_data[Bike_data['workingday']==1]
workingday_df = workingday_df.groupby(['hour'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
nworkingday_df=Bike_data[Bike_data['workingday']==0]
nworkingday_df = nworkingday_df.groupby(['hour'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
fig, axes = plt.subplots(1, 2,sharey = True)
workingday_df.plot(figsize=(15,5),title = 'The average number of rentals initiated per hour in the working day',ax=axes[0])
nworkingday_df.plot(figsize=(15,5),title = 'The average number of rentals initiated per hour in the nonworkdays',ax=axes[1])
plt.show()
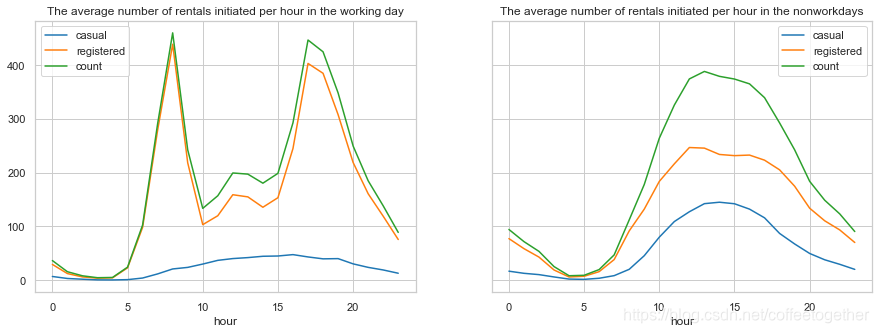
分析:
1.工作日对于会员用户上下班时间是两个用车高峰,而中午也会有一个小高峰,猜测可能是外出午餐的人;
2.而对临时用户起伏比较平缓,高峰期在17点左右;
3.并且会员用户的用车数量远超过临时用户。
4.对非工作日而言租赁数量随时间呈现一个正态分布,高峰在14点左右,低谷在4点左右,且分布比较均匀。
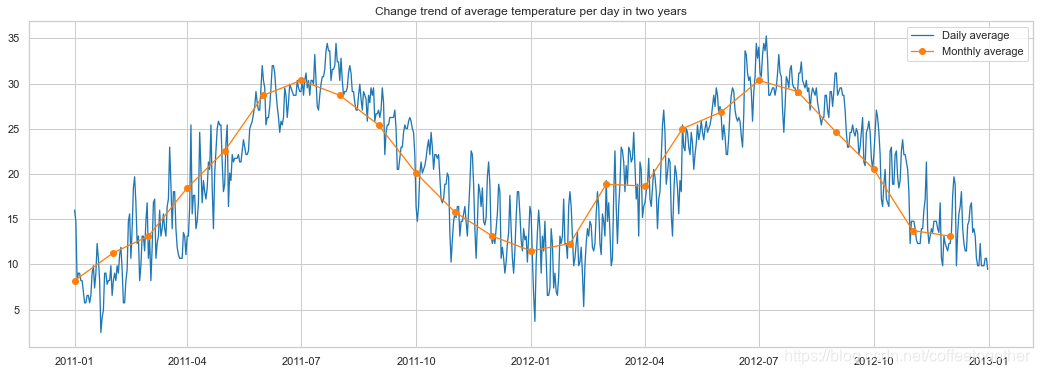
3.2 温度对租赁数量的影响
#数据按小时统计展示起来太麻烦,希望能够按天汇总取一天的气温中位数
temp_df = Bike_data.groupby(['date','weekday'], as_index=False).agg({'year':'mean',
'month':'mean',
'temp':'median'})
#由于测试数据集中没有租赁信息,会导致折线图有断裂,所以将缺失的数据丢弃
temp_df.dropna ( axis = 0 , how ='any', inplace = True )
#预计按天统计的波动仍然很大,再按月取日平均值
temp_month = temp_df.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'temp':'median'})
#将按天求和统计数据的日期转换成datetime格式
temp_df['date']=pd.to_datetime(temp_df['date'])
#将按月统计数据设置一列时间序列
temp_month.rename(columns={'weekday':'day'},inplace=True)
temp_month['date']=pd.to_datetime(temp_month[['year','month','day']])
#设置画框尺寸
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
#使用折线图展示总体租赁情况(count)随时间的走势
plt.plot(temp_df['date'] , temp_df['temp'] , linewidth=1.3 , label='Daily average')
ax.set_title('Change trend of average temperature per day in two years')
plt.plot(temp_month['date'] , temp_month['temp'] , marker='o', linewidth=1.3 ,
label='Monthly average')
ax.legend()
plt.show()
#按温度取租赁额平均值
# 查看三个租赁平均值随温度的变化
temp_rentals = Bike_data.groupby(['temp'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
temp_rentals .plot(title = 'The average number of rentals initiated per hour changes with the temperature')
plt.show()
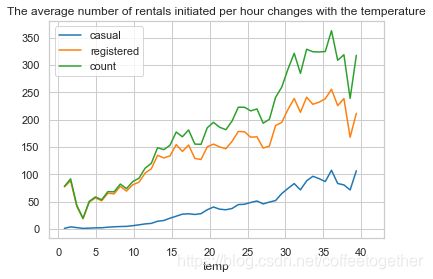
分析:
可观察到随气温上升租车数量总体呈现上升趋势,但在气温超过35时开始下降,在气温4度时达到最低点。
3.3 湿度对租赁数量的影响
humidity_df = Bike_data.groupby('date', as_index=False).agg({'humidity':'mean'})
humidity_df['date']=pd.to_datetime(humidity_df['date'])
#将日期设置为时间索引
humidity_df=humidity_df.set_index('date')
humidity_month = Bike_data.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'humidity':'mean'})
humidity_month.rename(columns={'weekday':'day'},inplace=True)
humidity_month['date']=pd.to_datetime(humidity_month[['year','month','day']])
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
plt.plot(humidity_df.index , humidity_df['humidity'] , linewidth=1.3,label='Daily average')
plt.plot(humidity_month['date'], humidity_month['humidity'] ,marker='o',
linewidth=1.3,label='Monthly average')
ax.legend()
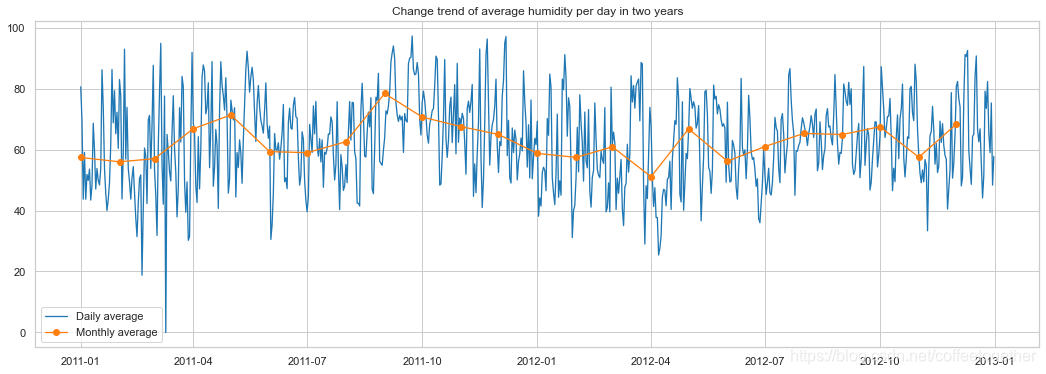
ax.set_title('Change trend of average humidity per day in two years')
plt.show()
# 同样查看租赁数量平均值岁湿度的变化情况
humidity_rentals = Bike_data.groupby(['humidity'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
humidity_rentals .plot (title = 'Average number of rentals initiated per hour in different humidity')
plt.show()
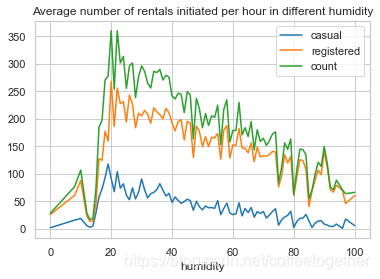
分析:
可以观察到在湿度20左右租赁数量迅速达到高峰值,此后缓慢递减。
3.4 年份、月份对租赁数量的影响
#数据按小时统计展示起来太麻烦,希望能够按天汇总
count_df = Bike_data.groupby(['date','weekday'], as_index=False).agg({'year':'mean',
'month':'mean',
'casual':'sum',
'registered':'sum',
'count':'sum'})
#由于测试数据集中没有租赁信息,会导致折线图有断裂,所以将缺失的数据丢弃
count_df.dropna ( axis = 0 , how ='any', inplace = True )
#预计按天统计的波动仍然很大,再按月取日平均值
count_month = count_df.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'casual':'mean',
'registered':'mean',
'count':'mean'})
#将按天求和统计数据的日期转换成datetime格式
count_df['date']=pd.to_datetime(count_df['date'])
#将按月统计数据设置一列时间序列
count_month.rename(columns={'weekday':'day'},inplace=True)
count_month['date']=pd.to_datetime(count_month[['year','month','day']])
#设置画框尺寸
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
#使用折线图展示总体租赁情况(count)随时间的走势
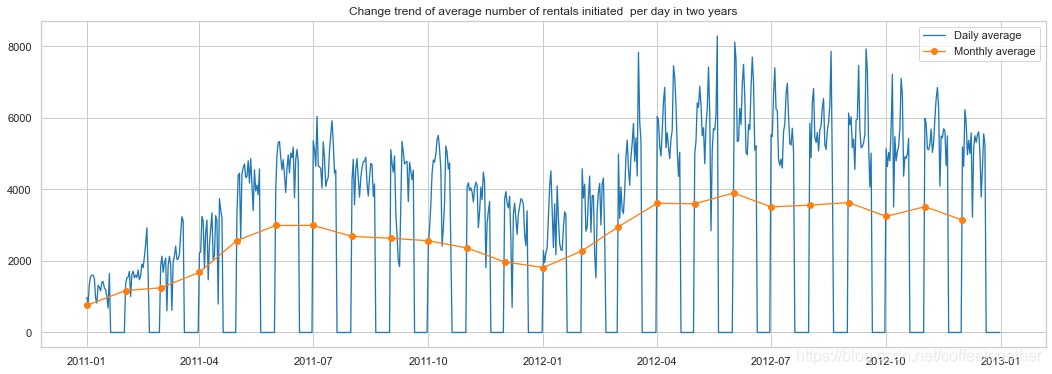
plt.plot(count_df['date'] , count_df['count'] , linewidth=1.3 , label='Daily average')
ax.set_title('Change trend of average number of rentals initiated per day in two years')
plt.plot(count_month['date'] , count_month['count'] , marker='o',
linewidth=1.3 , label='Monthly average')
ax.legend()
plt.show()
对月份进行分组,查看每个月份的租赁情况
day_df=Bike_data.groupby('date').agg({'year':'mean','season':'mean',
'casual':'sum', 'registered':'sum'
,'count':'sum','temp':'mean',
'atemp':'mean'})
season_df = day_df.groupby(['year','season'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
temp_df = day_df.groupby(['year','season'], as_index=True).agg({'temp':'mean',
'atemp':'mean'})
season_df.plot()
temp_df.plot()
plt.show()
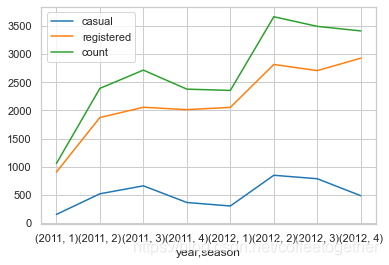
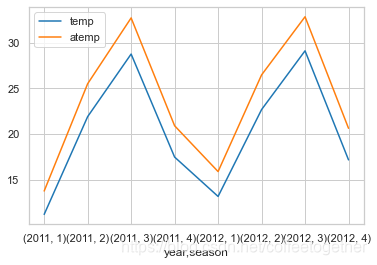
3.5 天气情况对出行情况的影响
count_weather = Bike_data.groupby('weather')
count_weather[['casual','registered','count']].count()
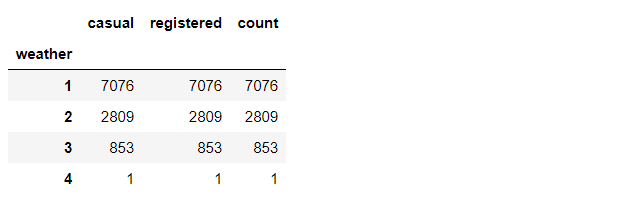
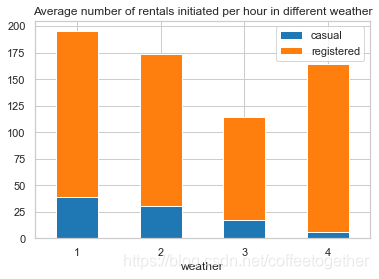
不同类型天气对应租赁数的平均值
weather_df = Bike_data.groupby('weather', as_index=True).agg({'casual':'mean',
'registered':'mean'})
weather_df.plot.bar(stacked=True,title = 'Average number of rentals initiated per hour in different weather')
plt.xticks(rotation=360)
plt.show()
查看天气等级为4的数据:
Bike_data[Bike_data['weather']==4]

3.6 风速对出行情况的影响
windspeed_df = Bike_data.groupby('date', as_index=False).agg({'windspeed_rfr':'mean'})
windspeed_df['date']=pd.to_datetime(windspeed_df['date'])
#将日期设置为时间索引
windspeed_df=windspeed_df.set_index('date')
windspeed_month = Bike_data.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'windspeed_rfr':'mean'})
windspeed_month.rename(columns={'weekday':'day'},inplace=True)
windspeed_month['date']=pd.to_datetime(windspeed_month[['year','month','day']])
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
plt.plot(windspeed_df.index , windspeed_df['windspeed_rfr'] , linewidth=1.3,label='Daily average')
plt.plot(windspeed_month['date'], windspeed_month['windspeed_rfr'] ,
marker='o', linewidth=1.3,label='Monthly average')
ax.legend()
ax.set_title('Change trend of average number of windspeed per day in two years')
plt.show()
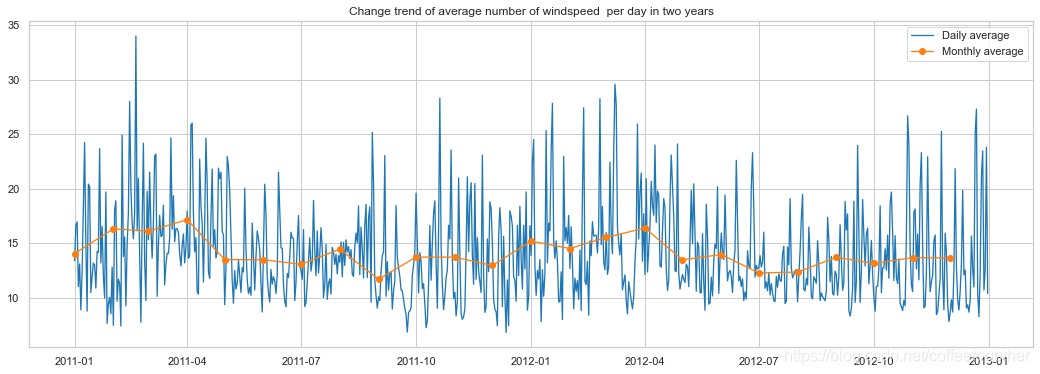
可以看出风速在2011年9月份和2011年12月到2012年3月份间波动和大,观察一下租赁人数随风速变化趋势,考虑到风速特别大的时候很少,如果取平均值会出现异常,所以按风速对租赁数量取最大值。
3.7 查看不同风速对租赁数量的影响
windspeed_rentals = Bike_data.groupby(['windspeed'], as_index=True).agg({'casual':'max',
'registered':'max',
'count':'max'})
windspeed_rentals .plot(title = 'Max number of rentals initiated per hour in different windspeed')
plt.show()
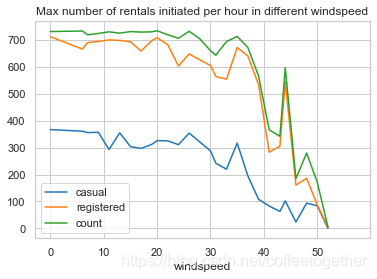
分析:风速在30以后,风速越大,相对于的租赁数就越少。但在分数在43-44附近出现了异常情况。
3.8 查看风速异常情况数据
# 查看风速大于40,租赁数量大于400的数据集
df2=Bike_data[Bike_data['windspeed']>40]
df2=df2[df2['count']>400]
df2

3.9 日期对出行的影响
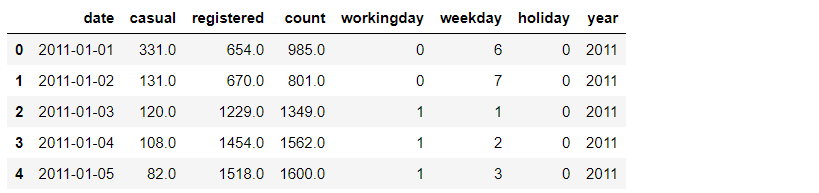
day_df = Bike_data.groupby(['date'], as_index=False).agg({'casual':'sum','registered':'sum',
'count':'sum', 'workingday':'mean',
'weekday':'mean','holiday':'mean',
'year':'mean'})
day_df.head()
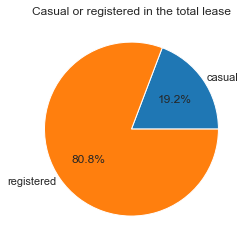
查看每天临时与会员占比情况
number_pei=day_df[['casual','registered']].mean()
number_pei

绘制不同占比情况饼图
plt.axes(aspect='equal')
plt.pie(number_pei, labels=['casual','registered'], autopct='%1.1f%%',
pctdistance=0.6 , labeldistance=1.05 , radius=1 )
plt.title('Casual or registered in the total lease')
plt.show()
3.10 工作日与非工作日的租赁情况
# 对非工作日进行分组
workingday_df=day_df.groupby(['workingday'], as_index=True).agg({'casual':'mean',
'registered':'mean'})
# 分别将不是工作日和是工作日的数据归为一类
workingday_df_0 = workingday_df.loc[0]
workingday_df_1 = workingday_df.loc[1]
# plt.axes(aspect='equal')
fig = plt.figure(figsize=(8,6))
plt.subplots_adjust(hspace=0.5, wspace=0.2) #设置子图表间隔
grid = plt.GridSpec(2, 2, wspace=0.5, hspace=0.5) #设置子图表坐标轴 对齐
plt.subplot2grid((2,2),(1,0), rowspan=2)
width = 0.3 # 设置条宽
# 绘制非工作日与工作日的临时借车数量和会员借车数量堆积图
p1 = plt.bar(workingday_df.index,workingday_df['casual'], width)
p2 = plt.bar(workingday_df.index,workingday_df['registered'],
width,bottom=workingday_df['casual'])
plt.title('Average number of rentals initiated per day')
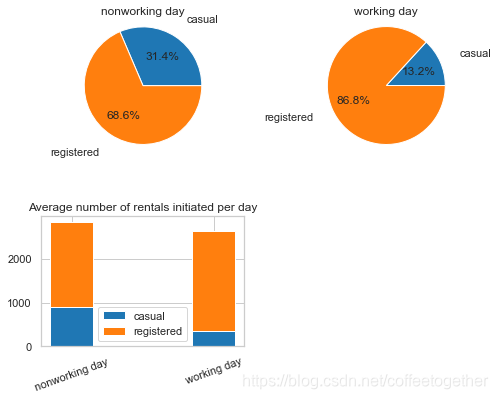
plt.xticks([0,1], ('nonworking day', 'working day'),rotation=20)
plt.legend((p1[0], p2[0]), ('casual', 'registered'))
# 绘制非工作日临时借车数量和会员借车数量占比饼图
plt.subplot2grid((2,2),(0,0))
plt.pie(workingday_df_0, labels=['casual','registered'], autopct='%1.1f%%',
pctdistance=0.6 , labeldistance=1.35 , radius=1.3)
plt.axis('equal')
plt.title('nonworking day')
# 绘制工作日临时借车数量和会员借车数量占比饼图
plt.subplot2grid((2,2),(0,1))
plt.pie(workingday_df_1, labels=['casual','registered'], autopct='%1.1f%%',
pctdistance=0.6 , labeldistance=1.35 , radius=1.3)
plt.title('working day')
plt.axis('equal')
3.11 星期对租赁数量的影响
weekday_df= day_df.groupby(['weekday'], as_index=True).agg({'casual':'mean', 'registered':'mean'})
weekday_df.plot.bar(stacked=True , title = 'Average number of rentals initiated per day by weekday')
plt.xticks(rotation=360)
plt.show()
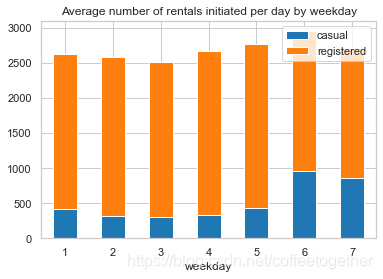
分析:
1.工作日会员用户出行数量较多,临时用户出行数量较少; 2.周末会员用户租赁数量降低,临时用户租赁数量增加。
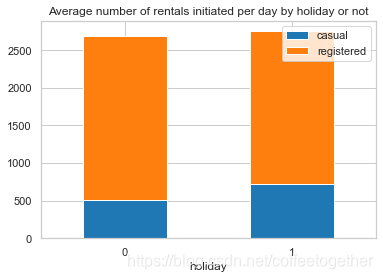
3.12 节假日的租赁情况
holiday_count=day_df.groupby('year', as_index=True).agg({'holiday':'sum'})
holiday_count

holiday_df = day_df.groupby('holiday', as_index=True).agg({'casual':'mean', 'registered':'mean'})
holiday_df.plot.bar(stacked=True , title = 'Average number of rentals initiated per day by holiday or not')
plt.xticks(rotation=360)
plt.show()
4 创建机器学习模型
根据前面的观察,决定将时段(hour)、温度(temp)、湿度(humidity)、年份(year)、月份(month)、季节(season)、天气等级(weather)、风速(windspeed_rfr)、星期几(weekday)、是否工作日(workingday)、是否假日(holiday),11项作为特征值
4.1 将多类别数据转换成二分类数据
由于CART决策树使用二分类,所以将多类别型数据使用one-hot转化成多个二分型类别
dummies_month = pd.get_dummies(Bike_data['month'], prefix= 'month')
dummies_season=pd.get_dummies(Bike_data['season'],prefix='season')
dummies_weather=pd.get_dummies(Bike_data['weather'],prefix='weather')
dummies_year=pd.get_dummies(Bike_data['year'],prefix='year')
#把5个新的DF和原来的表连接起来
Bike_data=pd.concat([Bike_data,dummies_month,dummies_season,dummies_weather,dummies_year],axis=1)
dummies_month.head()

Bike_data.head()
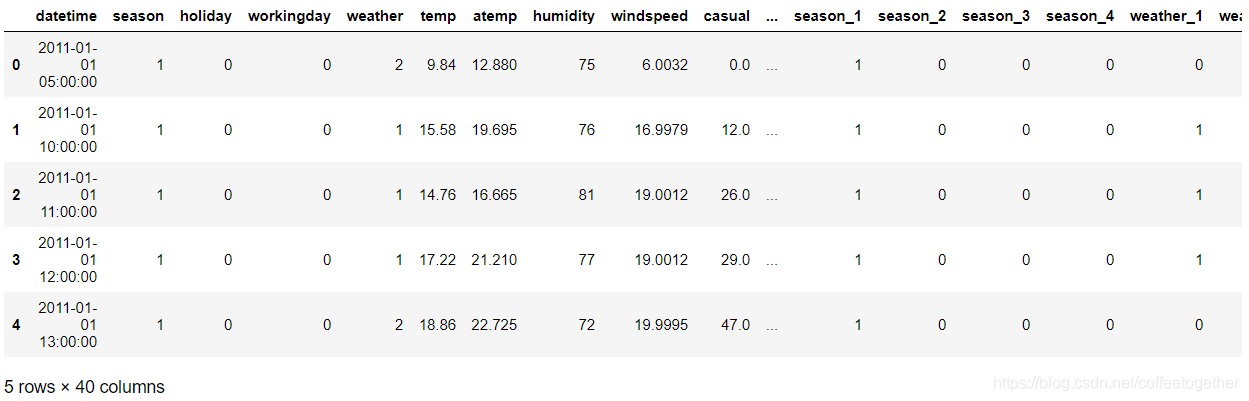
dataTrain = Bike_data[pd.notnull(Bike_data['count'])]
dataTest= Bike_data[~pd.notnull(Bike_data['count'])].sort_values(by=['datetime'])
datetimecol = dataTest['datetime']
yLabels=dataTrain['count']
yLabels_log=np.log(yLabels)
dataTrain.head()
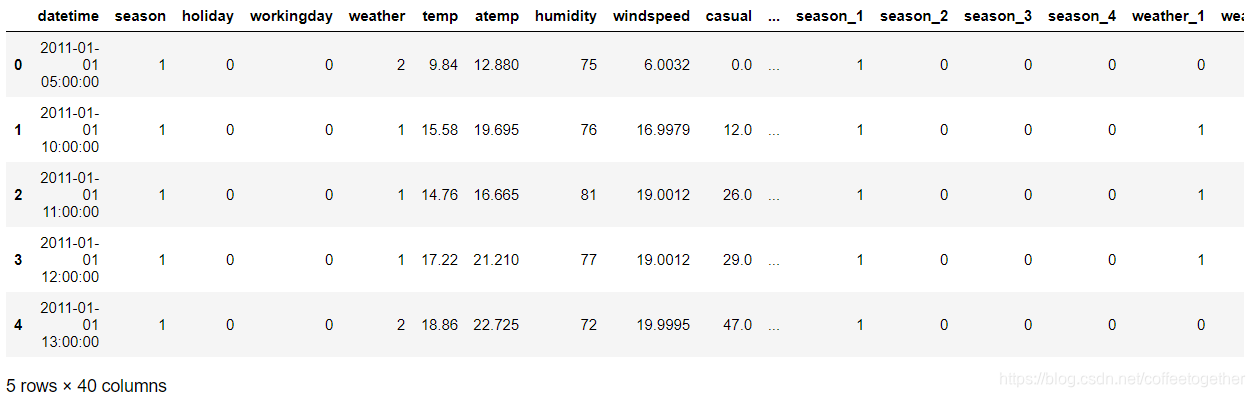
dataTest.head()
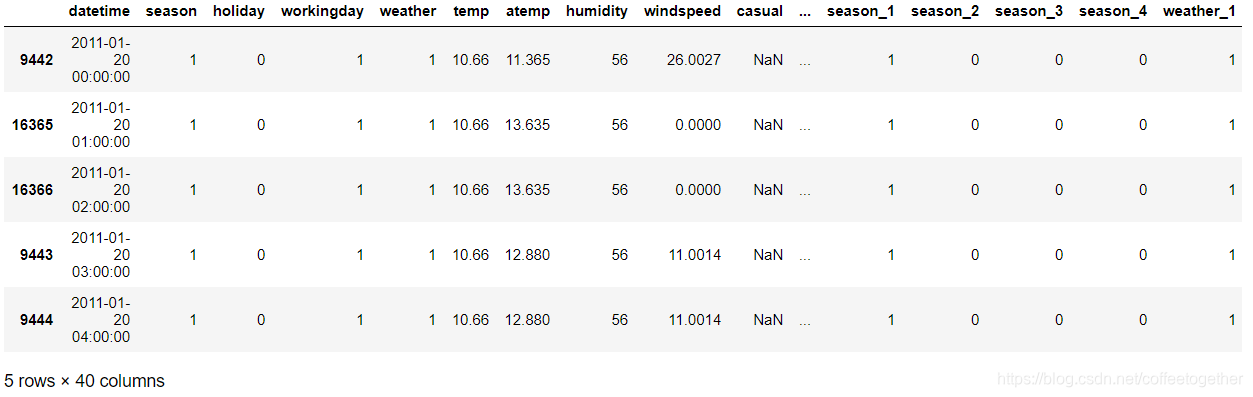
print(dataTrain.shape)
print(dataTest.shape)

4.2 将不需要的列删去,只留下二分类的特征数据
dropFeatures = ['casual' , 'count' , 'datetime' , 'date' , 'registered' ,
'windspeed' , 'atemp' , 'month','season','weather', 'year' ]
dataTrain = dataTrain.drop(dropFeatures , axis=1)
dataTest = dataTest.drop(dropFeatures , axis=1)
查看数据
dataTrain.head()

print(dataTrain.shape)
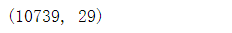
dataTest.head()

dataTest.shape

4.3 选择模型、训练模型
rfModel = RandomForestRegressor(n_estimators=1000 , random_state = 42)
# n_estimators代表森林中树的数量,
rfModel.fit(dataTrain , yLabels_log)
preds = rfModel.predict( X = dataTrain)
preds
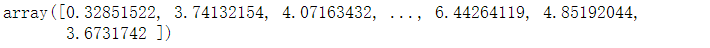
preds.shape

4.4 预测测试集数据
predsTest= rfModel.predict(X = dataTest)
# 将测试集数据以及对应的时间转化成DataFrame
submission=pd.DataFrame({'datetime':datetimecol , 'count':[max(0,x) for x in np.exp(predsTest)]})
submission.head()
submission.shape

保存数据
submission.to_csv('bike_predictions.csv',index=False)
4.5 使用逻辑回归模型对count进行预测
from sklearn.linear_model import LogisticRegression
# Logistic Regression 逻辑回归模型
logreg = LogisticRegression()
logreg.fit(dataTrain , yLabels_log.astype('int'))
Y_pred_logreg = logreg.predict(dataTrain)
acc_log = round(logreg.score(dataTrain , yLabels_log.astype('int'))*100,2)
# 预测结果
Y_pred_logreg.shape

Y_pred_logreg
Y_pred_logreg = logreg.predict(dataTest)
Y_pred_logreg.shape

Y_pred_logreg
submission2=pd.DataFrame({'datetime':datetimecol , 'count':[max(0,x) for x in np.exp(Y_pred_logreg)]})
submission2.head()
保存数据
submission2.to_csv('bike_predictions.csv',index=False)
智能推荐
Docker 快速上手学习入门教程_docker菜鸟教程-程序员宅基地
文章浏览阅读2.5w次,点赞6次,收藏50次。官方解释是,docker 容器是机器上的沙盒进程,它与主机上的所有其他进程隔离。所以容器只是操作系统中被隔离开来的一个进程,所谓的容器化,其实也只是对操作系统进行欺骗的一种语法糖。_docker菜鸟教程
电脑技巧:Windows系统原版纯净软件必备的两个网站_msdn我告诉你-程序员宅基地
文章浏览阅读5.7k次,点赞3次,收藏14次。该如何避免的,今天小编给大家推荐两个下载Windows系统官方软件的资源网站,可以杜绝软件捆绑等行为。该站提供了丰富的Windows官方技术资源,比较重要的有MSDN技术资源文档库、官方工具和资源、应用程序、开发人员工具(Visual Studio 、SQLServer等等)、系统镜像、设计人员工具等。总的来说,这两个都是非常优秀的Windows系统镜像资源站,提供了丰富的Windows系统镜像资源,并且保证了资源的纯净和安全性,有需要的朋友可以去了解一下。这个非常实用的资源网站的创建者是国内的一个网友。_msdn我告诉你
vue2封装对话框el-dialog组件_<el-dialog 封装成组件 vue2-程序员宅基地
文章浏览阅读1.2k次。vue2封装对话框el-dialog组件_
MFC 文本框换行_c++ mfc同一框内输入二行怎么换行-程序员宅基地
文章浏览阅读4.7k次,点赞5次,收藏6次。MFC 文本框换行 标签: it mfc 文本框1.将Multiline属性设置为True2.换行是使用"\r\n" (宽字符串为L"\r\n")3.如果需要编辑并且按Enter键换行,还要将 Want Return 设置为 True4.如果需要垂直滚动条的话将Vertical Scroll属性设置为True,需要水平滚动条的话将Horizontal Scroll属性设_c++ mfc同一框内输入二行怎么换行
redis-desktop-manager无法连接redis-server的解决方法_redis-server doesn't support auth command or ismis-程序员宅基地
文章浏览阅读832次。检查Linux是否是否开启所需端口,默认为6379,若未打开,将其开启:以root用户执行iptables -I INPUT -p tcp --dport 6379 -j ACCEPT如果还是未能解决,修改redis.conf,修改主机地址:bind 192.168.85.**;然后使用该配置文件,重新启动Redis服务./redis-server redis.conf..._redis-server doesn't support auth command or ismisconfigured. try
实验四 数据选择器及其应用-程序员宅基地
文章浏览阅读4.9k次。济大数电实验报告_数据选择器及其应用
随便推点
灰色预测模型matlab_MATLAB实战|基于灰色预测河南省社会消费品零售总额预测-程序员宅基地
文章浏览阅读236次。1研究内容消费在生产中占据十分重要的地位,是生产的最终目的和动力,是保持省内经济稳定快速发展的核心要素。预测河南省社会消费品零售总额,是进行宏观经济调控和消费体制改变创新的基础,是河南省内人民对美好的全面和谐社会的追求的要求,保持河南省经济稳定和可持续发展具有重要意义。本文建立灰色预测模型,利用MATLAB软件,预测出2019年~2023年河南省社会消费品零售总额预测值分别为21881...._灰色预测模型用什么软件
log4qt-程序员宅基地
文章浏览阅读1.2k次。12.4-在Qt中使用Log4Qt输出Log文件,看这一篇就足够了一、为啥要使用第三方Log库,而不用平台自带的Log库二、Log4j系列库的功能介绍与基本概念三、Log4Qt库的基本介绍四、将Log4qt组装成为一个单独模块五、使用配置文件的方式配置Log4Qt六、使用代码的方式配置Log4Qt七、在Qt工程中引入Log4Qt库模块的方法八、获取示例中的源代码一、为啥要使用第三方Log库,而不用平台自带的Log库首先要说明的是,在平时开发和调试中开发平台自带的“打印输出”已经足够了。但_log4qt
100种思维模型之全局观思维模型-67_计算机中对于全局观的-程序员宅基地
文章浏览阅读786次。全局观思维模型,一个教我们由点到线,由线到面,再由面到体,不断的放大格局去思考问题的思维模型。_计算机中对于全局观的
线程间控制之CountDownLatch和CyclicBarrier使用介绍_countdownluach于cyclicbarrier的用法-程序员宅基地
文章浏览阅读330次。一、CountDownLatch介绍CountDownLatch采用减法计算;是一个同步辅助工具类和CyclicBarrier类功能类似,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。二、CountDownLatch俩种应用场景: 场景一:所有线程在等待开始信号(startSignal.await()),主流程发出开始信号通知,既执行startSignal.countDown()方法后;所有线程才开始执行;每个线程执行完发出做完信号,既执行do..._countdownluach于cyclicbarrier的用法
自动化监控系统Prometheus&Grafana_-自动化监控系统prometheus&grafana实战-程序员宅基地
文章浏览阅读508次。Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,_-自动化监控系统prometheus&grafana实战
React 组件封装之 Search 搜索_react search-程序员宅基地
文章浏览阅读4.7k次。输入关键字,可以通过键盘的搜索按钮完成搜索功能。_react search