数学中的常见的距离公式-程序员宅基地
数学中的常见的距离公式
转载自:点击打开链接
- 1. 欧氏距离,最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中,如点 x = (x1,...,xn) 和 y = (y1,...,yn) 之间的距离为:
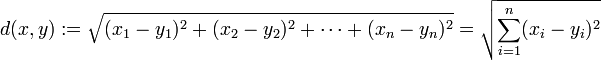
(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
(2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:
(3)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
也可以用表示成向量运算的形式:
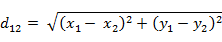
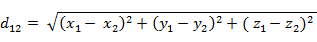
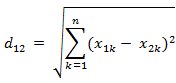
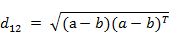
其上,二维平面上两点欧式距离,代码可以如下编写:
- //unixfy:计算欧氏距离
- double euclideanDistance(const vector<double>& v1, const vector<double>& v2)
- {
- assert(v1.size() == v2.size());
- double ret = 0.0;
- for (vector<double>::size_type i = 0; i != v1.size(); ++i)
- {
- ret += (v1[i] - v2[i]) * (v1[i] - v2[i]);
- }
- return sqrt(ret);
- }
- 2. 曼哈顿距离,我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为:
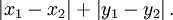 ,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离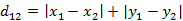 (2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
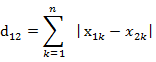
- 3. 切比雪夫距离,若二个向量或二个点p 、and q,其座标分别为
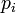 及
及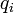 ,则两者之间的切比雪夫距离定义如下:
,则两者之间的切比雪夫距离定义如下: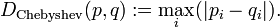 ,
,
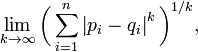 ,因此切比雪夫距离也称为L∞度量。
,因此切比雪夫距离也称为L∞度量。
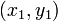 及
及
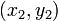 ,则切比雪夫距离为:
,则切比雪夫距离为:
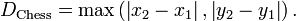 。
。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离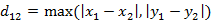 (2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的切比雪夫距离
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的切比雪夫距离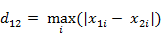 这个公式的另一种等价形式是
这个公式的另一种等价形式是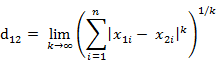
- 4. 闵可夫斯基距离(Minkowski Distance),闵氏距离不是一种距离,而是一组距离的定义。
(1) 闵氏距离的定义两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为: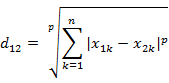 其中p是一个变参数。当p=1时,就是曼哈顿距离当p=2时,就是欧氏距离当p→∞时,就是切比雪夫距离根据变参数的不同,闵氏距离可以表示一类的距离。
其中p是一个变参数。当p=1时,就是曼哈顿距离当p=2时,就是欧氏距离当p→∞时,就是切比雪夫距离根据变参数的不同,闵氏距离可以表示一类的距离。
-
5. 标准化欧氏距离 (Standardized Euclidean distance ),标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。至于均值和方差标准化到多少,先复习点统计学知识。
假设样本集X的数学期望或均值(mean)为m,标准差(standard deviation,方差开根)为s,那么X的“标准化变量”X*表示为:(X-m)/s,而且标准化变量的数学期望为0,方差为1。
即,样本集的标准化过程(standardization)用公式描述就是:
标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差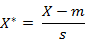
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:
如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。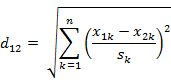
-
6. 马氏距离(Mahalanobis Distance)
(1)马氏距离定义
有M个样本向量X1~Xm, 协方差矩阵记为S,均值记为向量μ,则其中样本向量X到u的马氏距离表示为:
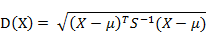 ( 协方差矩阵中每个元素是各个矢量元素之间的协方差Cov(X,Y),Cov(X,Y) = E{ [X-E(X)] [Y-E(Y)]},其中E为数学期望)
( 协方差矩阵中每个元素是各个矢量元素之间的协方差Cov(X,Y),Cov(X,Y) = E{ [X-E(X)] [Y-E(Y)]},其中E为数学期望)
而其中向量Xi与Xj之间的马氏距离定义为:
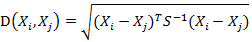
若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了:
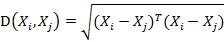
也就是欧氏距离了。
若协方差矩阵是对角矩阵,公式变成了标准化欧氏距离。
(2)马氏距离的优缺点:量纲无关,排除变量之间的相关性的干扰。「 微博上的seafood高清版点评道:原来马氏距离是根据协方差矩阵演变,一直被老师误导了,怪不得看Killian在05年NIPS发表的LMNN论文时候老是看到协方差矩阵和半正定,原来是这回事」 - 7、巴氏距离(Bhattacharyya Distance),在统计中,Bhattacharyya距离测量两个离散或连续概率分布的相似性。它与衡量两个统计样品或种群之间的重叠量的Bhattacharyya系数密切相关。Bhattacharyya距离和Bhattacharyya系数以20世纪30年代曾在印度统计研究所工作的一个统计学家A. Bhattacharya命名。同时,Bhattacharyya系数可以被用来确定两个样本被认为相对接近的,它是用来测量中的类分类的可分离性。
(1)巴氏距离的定义对于离散概率分布 p和q在同一域 X,它被定义为:
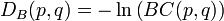
其中:
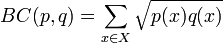
是Bhattacharyya系数。对于连续概率分布,Bhattacharyya系数被定义为:
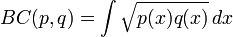
在这两种情况下,巴氏距离
并没有服从三角不等式.(值得一提的是,Hellinger距离不服从三角不等式
)。
对于多变量的高斯分布,
,
和是手段和协方差的分布。
需要注意的是,在这种情况下,第一项中的Bhattacharyya距离与马氏距离有关联。(2)Bhattacharyya系数Bhattacharyya系数是两个统计样本之间的重叠量的近似测量,可以被用于确定被考虑的两个样本的相对接近。计算Bhattacharyya系数涉及集成的基本形式的两个样本的重叠的时间间隔的值的两个样本被分裂成一个选定的分区数,并且在每个分区中的每个样品的成员的数量,在下面的公式中使用
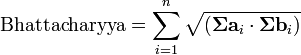
考虑样品a 和 b ,n是的分区数,并且,
被一个 和 b i的日分区中的样本数量的成员。更多介绍请参看: http://en.wikipedia.org/wiki/Bhattacharyya_coefficient。
- 8. 汉明距离(Hamming distance), 两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。例如字符串“1111”与“1001”之间的汉明距离为2。应用:信息编码(为了增强容错性,应使得编码间的最小汉明距离尽可能大)。
或许,你还没明白我再说什么,不急,看下 上篇blog中第78题的第3小题整理的一道面试题目,便一目了然了。如下图所示:
- //动态规划:
- //f[i,j]表示s[0...i]与t[0...j]的最小编辑距离。
- f[i,j] = min { f[i-1,j]+1, f[i,j-1]+1, f[i-1,j-1]+(s[i]==t[j]?0:1) }
- //分别表示:添加1个,删除1个,替换1个(相同就不用替换)。
与此同时, 面试官还可以继续问下去:那么,请问,如何设计一个比较两篇文章相似性的算法?( 这个问题的讨论可以看看这里: http://t.cn/zl82CAH,及这里关于simhash算法的介绍: http://www.cnblogs.com/linecong/archive/2010/08/28/simhash.html ),接下来,便引出了下文关于夹角余弦的讨论。(上篇blog中第78题的第3小题给出了多种方法,读者可以参看之。同时,程序员编程艺术系列第二十八章将详细阐述这个问题)
- 9. 夹角余弦(Cosine) ,几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。
(1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
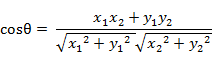
(2) 两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦
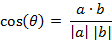
类似的,对于两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度,即:
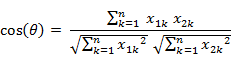
夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。
- 10. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
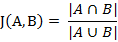
杰卡德相似系数是衡量两个集合的相似度一种指标。(2) 杰卡德距离与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示:
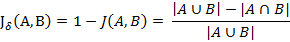
杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。(3) 杰卡德相似系数与杰卡德距离的应用可将杰卡德相似系数用在衡量样本的相似度上。
举例:样本A与样本B是两个n维向量,而且所有维度的取值都是0或1,例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。M 11 :样本A与B都是1的维度的个数M0 1:样本A是0,样本B是1的维度的个数M10:样本A是1,样本B是0 的维度的个数M 00:样本A与B都是0的维度的个数依据上文给的杰卡德相似系数及杰卡德距离的相关定义,样本A与B的杰卡德相似系数J可以表示为:
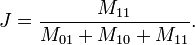
这里M 11+ M 01+ M 10可理解为A与B的并集的元素个数,而M 11是A与B的交集的元素个数。而样本A与B的杰卡德距离表示为J':
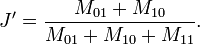
- 11.皮尔逊系数(Pearson Correlation Coefficient)
( 其中,E为数学期望或均值,D为方差,D开根号为标准差,E{ [X-E(X)] [Y-E(Y)]}称为随机变量X与Y的协方差,记为Cov(X,Y),即Cov(X,Y) = E{ [X-E(X)] [Y-E(Y)]},而两个变量之间的协方差和标准差的商则称为随机变量X与Y的相关系数,记为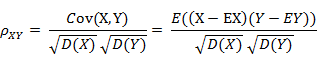
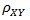 )
)
- 当相关系数为0时,X和Y两变量无关系。
- 当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
- 当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
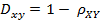
OK,接下来,咱们来重点了解下皮尔逊相关系数。在统计学中,皮尔逊积矩相关系数(英语:Pearson product-moment correlation coefficient,又称作 PPMCC或PCCs, 用r表示)用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关在自然科学领域中,该系数广泛用于度量两个变量之间的相关程度。它是由卡尔·皮尔逊从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来的。这个相关系数也称作“皮尔森相关系数r”。
(1)皮尔逊系数的定义:两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
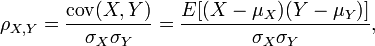
以上方程定义了总体相关系数, 一般表示成希腊字母ρ(rho)。基于样本对协方差和方差进行估计,可以得到样本标准差, 一般表示成r:
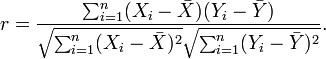
一种等价表达式的是表示成标准分的均值。基于(Xi, Yi)的样本点,样本皮尔逊系数是
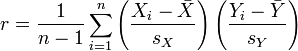
其中、
及
,分别是标准分、样本平均值和样本标准差。
或许上面的讲解令你头脑混乱不堪,没关系,我换一种方式讲解,如下:假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
- 公式一:
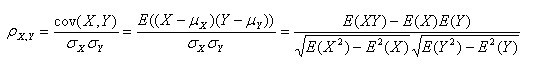
注:勿忘了上面说过,“皮尔逊相关系数定义为两个变量之间的协方差和标准差的商”,其中标准差的计算公式为: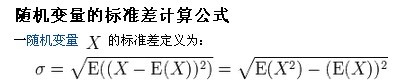
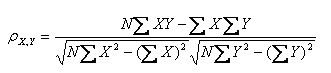
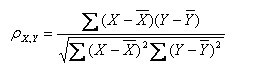
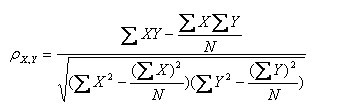
(2)皮尔逊相关系数的适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
- 两个变量之间是线性关系,都是连续数据。
- 两个变量的总体是正态分布,或接近正态的单峰分布。
- 两个变量的观测值是成对的,每对观测值之间相互独立。
(3)如何理解皮尔逊相关系数
rubyist:皮尔逊相关系数理解有两个角度
其一, 按照高中数学水平来理解, 它很简单, 可以看做将两组数据首先做Z分数处理之后, 然后两组数据的乘积和除以样本数,Z分数一般代表正态分布中, 数据偏离中心点的距离.等于变量减掉平均数再除以标准差.(就是高考的标准分类似的处理)
样本标准差则等于变量减掉平均数的平方和,再除以样本数,最后再开方,也就是说,方差开方即为标准差,样本标准差计算公式为:
所以, 根据这个最朴素的理解,我们可以将公式依次精简为:
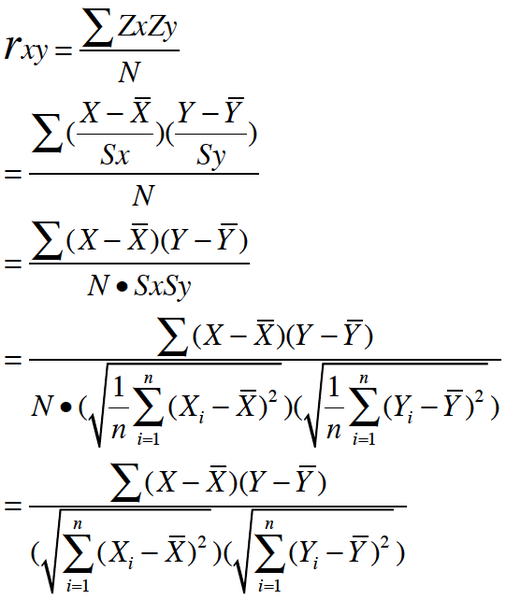
其二, 按照大学的线性数学水平来理解, 它比较复杂一点,可以看做是两组数据的向量夹角的余弦。下面是关于此皮尔逊系数的几何学的解释,先来看一幅图,如下所示:
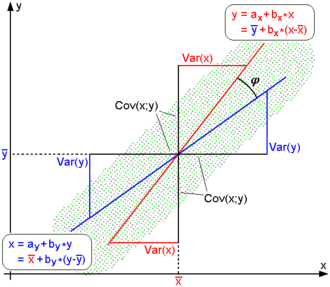
回归直线: y=gx(x) [红色] 和 x=gy(y) [蓝色]
如上图,对于没有中心化的数据, 相关系数与两条可能的回归线y=gx(x) 和 x=gy(y) 夹角的余弦值一致。
对于没有中心化的数据 (也就是说, 数据移动一个样本平均值以使其均值为0), 相关系数也可以被视作由两个随机变量 向量 夹角 的 余弦值(见下方)。
举个例子,例如,有5个国家的国民生产总值分别为 10, 20, 30, 50 和 80 亿美元。 假设这5个国家 (顺序相同) 的贫困百分比分别为 11%, 12%, 13%, 15%, and 18% 。 令 x 和 y 分别为包含上述5个数据的向量: x = (1, 2, 3, 5, 8) 和 y = (0.11, 0.12, 0.13, 0.15, 0.18)。
利用通常的方法计算两个向量之间的夹角 (参见 数量积), 未中心化 的相关系数是:
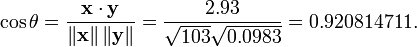
我们发现以上的数据特意选定为完全相关: y = 0.10 + 0.01 x。 于是,皮尔逊相关系数应该等于1。将数据中心化 (通过E(x) = 3.8移动 x 和通过 E(y) = 0.138 移动 y ) 得到 x = (−2.8, −1.8, −0.8, 1.2, 4.2) 和 y = (−0.028, −0.018, −0.008, 0.012, 0.042), 从中
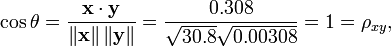
(4)皮尔逊相关的约束条件
从以上解释, 也可以理解皮尔逊相关的约束条件:
- 1 两个变量间有线性关系
- 2 变量是连续变量
- 3 变量均符合正态分布,且二元分布也符合正态分布
- 4 两变量独立
在实践统计中,一般只输出两个系数,一个是相关系数,也就是计算出来的相关系数大小,在-1到1之间;另一个是独立样本检验系数,用来检验样本一致性。
智能推荐
Kotlin 解压缩_kotlin 对上传的压缩包进行分析-程序员宅基地
文章浏览阅读638次。fun unZip(zipFile: String, context: Context) { var outputStream: OutputStream? = null var inputStream: InputStream? = null try { val zf = ZipFile(zipFile) val entries = zf.entries() while (en..._kotlin 对上传的压缩包进行分析
64K方法数限制解决办法_java函数大于64k编译失败-程序员宅基地
文章浏览阅读1.9k次。随着业务逻辑越来越多,业务模块也越来越大,不可避免会遇到64K方法数的限制。最直观的表现就是编译报错:较早版本的编译系统中,错误内容如下:Conversion to Dalvik format failed:Unable to execute dex: method ID not in [0, 0xffff]: 65536较新版本的编译系统中,错误内容如下:trouble writing outp_java函数大于64k编译失败
案例分享——低压电力线载波通信模组(借助电源线实现远距离数据传输、宽压输入、波特率范围广、应用场景多样化)_电力载波模块csdn-程序员宅基地
文章浏览阅读2k次,点赞7次,收藏10次。物联网领域,有很多数据通信场景,因为原设备整体系统结构、运行环境等方面的限制,需求在不增加通信数据线缆的情况下实现数据的远程传输,因为特殊应用场景下考虑到环境的限制,还不能使用常规的无线通信手段,所以借助电源线缆进行传输的电力线载波技术应运而生,本次博文给大家分享的就是博主完全自主研发的低压电力线载波通信模组。_电力载波模块csdn
密码学基础_密码体制的五个要素-程序员宅基地
文章浏览阅读7.4k次。密码学基本概念 密码学(Cryptology)是结合数学、计算机科学、电子与通信等学科于一体的交叉学科,研究信息系统安全的科学。起源于保密通信技术。具体来讲,研究信息系统安全保密和认证的一门科学。 密码编码学,通过变换消息(对信息编码)使其保密的科学和艺术 密码分析学,在未知密钥的情况下从密文推_密码体制的五个要素
python支持中文路径_基于python 处理中文路径的终极解决方法-程序员宅基地
文章浏览阅读1.9k次。1 、据说python3就没有这个问题了2 、u'字符串' 代表是unicode格式的数据,路径最好写成这个格式,别直接跟字符串'字符串'这类数据相加,相加之后type就是str,这样就会存在解码失误的问题。别直接跟字符串'字符串'这类数据相加别直接跟字符串'字符串'这类数据相加别直接跟字符串'字符串'这类数据相加unicode类型别直接跟字符串'字符串'这类数据相加说四遍3 、有些读取的方式偏偏..._python 路径 中文
阿里云 B 站直播首秀,用 Serverless 搭个游戏机?-程序员宅基地
文章浏览阅读107次。最近,阿云 B 站没声音,是在憋大招!8月5日周四 19:00 是阿里云的直播首秀,给大家请来了 Forrester 评分世界第一的 Serverless 团队产品经理江昱,给大家在线...._阿里云直播b站
随便推点
AS 3.1.3连续依赖多个Module,导致访问不到Module中的类_为什么as在一个包下建了多个module,缺无法打开了-程序员宅基地
文章浏览阅读1.1k次。我好苦啊,半夜还在打代码。还出bug,狗日的。问题是这样的:我在新建的项目里,建了两个Module: fiora-ec和fiora-core。项目的依赖顺序是这样的,App依赖fiora-ec,fiora-ec又依赖于fiora-core,因为这种依赖关系,所有可以在app和fiora-ec中删除一些不必要的引入,比如这个玩意儿:com.android.support:appcompat-v7:..._为什么as在一个包下建了多个module,缺无法打开了
Magento 常用插件二-程序员宅基地
文章浏览阅读1.4k次。1. SMTP 插件 URL:http://www.magentocommerce.com/magento-connect/TurboSMTP/extension/4415/aschroder_turbosmtp KEY:magento-community/Aschroder_TurboSmtp 2. Email Template Adapter..._magento extension pour ricardo.ch
【连载】【FPGA黑金开发板】Verilog HDL那些事儿--低级建模的资源(六)-程序员宅基地
文章浏览阅读161次。声明:本文为原创作品,版权归akuei2及黑金动力社区共同所有,如需转载,请注明出处http://www.cnblogs.com/kingst/ 2.5 低级建模的资源 低级建模有讲求资源的分配,目的是使用“图形”来提高建模的解读性。 图上是低级建模最基本的建模框图,估计大家在实验一和实验二已经眼熟过。功能模块(低级功能模块)是一个水平的长方形,而控制模块(低级控制模块)是矩形。组..._cyclone ep2c8q208c黑金开发板
R语言实用案例分析-1_r语言案例分析-程序员宅基地
文章浏览阅读2.2w次,点赞10次,收藏63次。在日常生活和实际应用当中,我们经常会用到统计方面的知识,比如求最大值,求平均值等等。R语言是一门统计学语言,他可以方便的完成统计相关的计算,下面我们就来看一个相关案例。1. 背景最近西安交大大数据专业二班,开设了Java和大数据技术课程,班级人数共100人。2. 需求通过R语言完成该100位同学学号的生成,同时使用R语言模拟生成Java和大数据技术成绩,成绩满分为100,需要满足正_r语言案例分析
Java知识体系总结(2024版),这一次带你搞懂Spring代理创建过程-程序员宅基地
文章浏览阅读639次,点赞11次,收藏26次。虽然我个人也经常自嘲,十年之后要去成为外卖专员,但实际上依靠自身的努力,是能够减少三十五岁之后的焦虑的,毕竟好的架构师并不多。架构师,是我们大部分技术人的职业目标,一名好的架构师来源于机遇(公司)、个人努力(吃得苦、肯钻研)、天分(真的热爱)的三者协作的结果,实践+机遇+努力才能助你成为优秀的架构师。如果你也想成为一名好的架构师,那或许这份Java成长笔记你需要阅读阅读,希望能够对你的职业发展有所帮助。一个人可以走的很快,但一群人才能走的更远。
车辆动力学及在Unity、UE4中的实现_unity 车辆动力学模型-程序员宅基地
文章浏览阅读3.9k次,点赞9次,收藏53次。受力分析直线行驶时的车轮受力如下:水平方向上,所受合力为:F=Ft+Fw+FfF=F_t+F_w+F_fF=Ft+Fw+Ff其中,FtF_tFt为牵引力,FwF_wFw为空气阻力,FfF_fFf为滚动阻力,下面我们将逐个介绍。驱动力先来说扭矩,扭矩是使物体发生旋转的一个特殊力矩,等于力和力臂的乘积,单位为N∙mN∙mN∙m:设驱动轴的扭矩为TtT_tTt,车轮半径为rrr,那么牵引力:Ft=Tt⁄rF_t=T_t⁄rFt=Tt⁄r如何求得驱动轴扭矩TtT_tTt呢?_unity 车辆动力学模型