使用java和scala编写spark-WordCount示例_java scalawordcountlocal-程序员宅基地
技术标签: wordCount spark scala Sundry
前言:
最近博主在学习spark相关知识,感觉是个挺不错的框架,它的分布式处理大数据集的思想还是值得我们好好学习的。
个人感觉以后java开发肯定不仅仅是SSM这一套东西了,当数据量越来越大时,我们需要学习使用这些大数据工具。
本次博客学习使用java和scala两种方式来开发spark的wordCount示例
由于采用spark的local模式,所以我们可以完全不用启动spark,使用eclipse,添加spark相关jar包在本地跑就可以了
准备工作:
1.准备数据
在本地创建spark.txt文件,并添加一些语句
2.eclipse工具,用于java开发
3.scala ide for eclipse用于scala开发
下载界面:http://scala-ide.org/download/sdk.html
4.本地安装JDK8(由于笔者使用的spark版本为2.2.0,故需要jdk8及以上版本)
5.本地安装scala(一定要注意,scala的版本需要与spark的版本匹配,当spark版本为2.2.0时,scala版本为2.11,不能太高也不能低,一定要注意,否则创建scala project会报错)
1.java开发wordCount程序(使用工具eclipse)
1)创建maven项目 spark
2)添加Maven依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<scala.version>2.11</scala.version>
<spark.version>2.2.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>3)在spark项目中添加WordCountJava类,代码如下
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class WordCountJava {
public static void main(String[] args) {
// 1.创建SparkConf
SparkConf sparkConf = new SparkConf()
.setAppName("wordCountLocal")
.setMaster("local");
// 2.创建JavaSparkContext
// SparkContext代表着程序入口
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// 3.读取本地文件
JavaRDD<String> lines = sc.textFile("C:/Users/lucky/Desktop/spark.txt");
// 4.每行以空格切割
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String t) throws Exception {
return Arrays.asList(t.split(" ")).iterator();
}
});
// 5.转换为 <word,1>格式
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String t) throws Exception {
return new Tuple2<String, Integer>(t, 1);
}
});
// 6.统计相同Word的出现频率
JavaPairRDD<String, Integer> wordCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 7.执行action,将结果打印出来
wordCount.foreach(new VoidFunction<Tuple2<String,Integer>>() {
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1()+" "+t._2());
}
});
// 8.主动关闭SparkContext
sc.stop();
}
}4)执行(右键 run as java application即可)
2.scala开发wordCount程序(使用工具scala ide for eclipse)
1)创建scala project ,命名为spark-study
2)转变为maven项目
右键点击spark-study,选中configure,选择其中的convert to maven project选项,等待成功即可
3)添加maven依赖(同上)
注意:笔者使用到spark版本为2.2.0,由于spark版本与scala版本不匹配,导致报以下错误
breeze_2.11-0.13.1.jar of spark-study build path is cross-compiled with an incompatible version of Scala (2.11.0). In case this report is mistaken, this check can be disabled in the compiler preference page.如果读者看到这个报错,就先检查一下自己的scala版本与spark版本是否匹配,如何确定呢,可以在https://mvnrepository.com/artifact/org.apache.spark/spark-core maven仓库中确定,
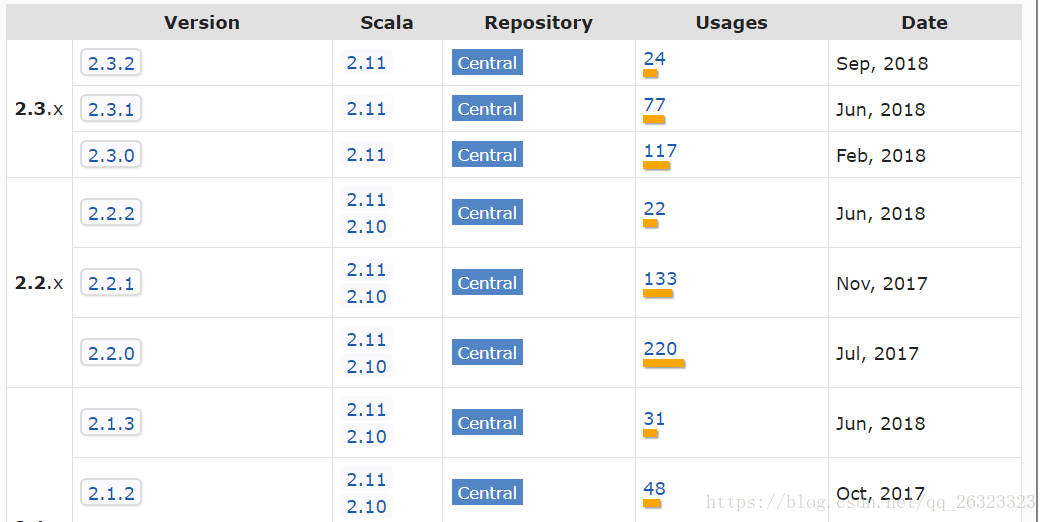
仓库中有spark对应的scala版本,严格按照这个来安装本地的scala即可,否则报错
4)在spark-study项目中创建scala object,命名为WordCountScala,代码如下
object WordCountScala {
def main(args: Array[String]): Unit = {
// 注意选择local模式
val sparkConf = new SparkConf().setMaster("local").setAppName("wordCount");
val sc = new SparkContext(sparkConf)
// 读取本地文件
val lines = sc.textFile("C:/Users/lucky/Desktop/spark.txt");
val words = lines.flatMap(line => line.split(" "))
val pairs = words.map(word => (word,1))
val wordCounts = pairs.reduceByKey((a,b) => (a+b))
// 最后执行action 操作
wordCounts.foreach(wordcount => println(wordcount._1 +" " + wordcount._2))
}
}以上这种方式,我们同样可以简写为:
val sparkConf = new SparkConf().setMaster("local").setAppName("wordCount");
val sc = new SparkContext(sparkConf)
sc.textFile("C:/Users/lucky/Desktop/spark.txt")
.flatMap(line => line.split(" "))
.map(word => (word,1))
.reduceByKey((a,b) => (a+b))
.foreach(wordcount => println(wordcount._1 +" " + wordcount._2))5)执行wordCount(右键run as Scala Application即可)
可以看到在本地控制台打印了結果
智能推荐
IRLR2705TRPBF-VB一种N沟道TO252封装MOS管-程序员宅基地
文章浏览阅读341次,点赞11次,收藏7次。3. **开态电阻(RDS(ON)):** 24mΩ @ VGS=10V, VGS=20V - 这表示在不同的门源电压下,器件的导通状态时的电阻。4. **阈值电压(Vth):** 1.8V - 这是器件的阈值电压,即MOSFET开始导通的门源电压。1. **额定电压(V):** 60V - 这表示器件能够在60V的电压下正常工作。2. **额定电流(A):** 45A - 这表示器件可以承受的最大电流为45安培。1. **电源模块:** 由于其较高的额定电压和电流,适用于设计稳定可靠的电源模块。
视频监控业务平台智能边缘分析一体机客流量统计算法在公共交通领域应用_视觉 客流 site:csdn.net-程序员宅基地
文章浏览阅读327次,点赞10次,收藏10次。随着城市公共交通网络的不断扩大和完善,智能边缘分析一体机的应用将逐渐覆盖更广泛的区域,并与其他交通管理系统进行整合,实现全面、高效的客流统计和管理。这些发展方向将推动智能边缘分析一体机在公共交通领域的客流统计中发挥更加重要的作用,为城市交通管理和运营带来更多创新和解决方案,进一步优化人们的出行体验,建设更便捷、高效、安全的城市交通系统。随着技术的不断进步和应用场景的不断拓展,智能边缘分析一体机将在未来为公共交通发展提供更多创新和解决方案,助力打造高效、安全、便捷的城市出行环境。_视觉 客流 site:csdn.net
合肥练车记_合肥滨湖车管所科目四考场在哪里-程序员宅基地
文章浏览阅读3k次。吐槽首先吐槽一下123123以及交管所,在APP上根本看不到考试时间,想知道当天几点考试,还要当天到车管所才能看到。如果上午8点半到了,结果下午才考试,难道要等一下午吗? 我是自主预约的科目四,不知道当天什么时候考试,问了教练,教练表示也不知道,看考场那边安排。如果我当时预约周一或者周四的考试,教练是知道时间的,只可惜忘记了。为了拿到驾照,我早起一次,9点左右就到了车管所,进去之后发现我所在的驾校是下午1点钟才开始考,我此时心里一万个草泥马,,无奈,我显然是不能在这里傻等到下午1点钟再考试了。那真的太难_合肥滨湖车管所科目四考场在哪里
qemu源码编译以及启动arm应用程序和arm镜像_qemu arm源码编译-程序员宅基地
文章浏览阅读655次。源码下载git clone --recursive https://github.com/qemu/qemu.git编译源码 mkdir build cd build mkdir qemu_arm ../configure --target-list=arm-softmmu --prefix=./qemu_arm运行arm 程序运行arm镜像# 其他注意事项1.下载源..._qemu arm源码编译
2016年腾讯实习生面试技术面一面二面_技术一面没说二面-程序员宅基地
文章浏览阅读4.5k次。2016年4月10日晚上我接到初试的通知,当时也知道表哥已经内推进了微信,敬佩之余也要奋发图强,要拿一个offer回来。当晚看了一下项目源码,看了一会jvm以及android listview的缓存机制便睡觉面试。 4月11日上午11点,由于HR的过早通知,导致在师兄门口呆了半个小时。11点半准备一面,得知我做得项目其中有一个是关于华工食堂的,师兄觉得特别好玩,才透露出他是我直系大师兄_技术一面没说二面
代码属性图之-joern简易教程_joern 教程-程序员宅基地
文章浏览阅读4.4k次,点赞4次,收藏14次。一 Joern实例分析在Joern中发现了一个实例教程,本着学习的态度,尝试复现这个过程,以增加自己的经验!严谨转载,欢迎讨论!1 正常安装joern以及neo4j。2 建议下载教程中的VLC版本。cd $JOERN #joern目录mkdir tutorial; cd tutorial #创建并转入tutorialwget http://download.videolan...._joern 教程
随便推点
Hadoop Metrics2实现原理_hadoop-metrics2-程序员宅基地
文章浏览阅读1.8k次。Hadoop Metrics2的实现应该是在14年左右就已经非常成熟了,研究的人也比较多了。一个出现很久的东西,并非没有学习价值。如Metrics2 和之前的Metrics 一代做了哪些改进?如果我们自己设计一套Metrics信息,哪些是可以借鉴的地方?所有Source 和Sink全部是可配置的(和我们常见的Log4j配置一样),这样可以在不修改源码的情况下,自定义Metrics的监控Met..._hadoop-metrics2
解决(PostgreSQL)restore数据库时提示python27.dll缺失问题_pg数据库恢复时缺失python7.dll-程序员宅基地
文章浏览阅读407次。error :(PostgreSQL)restore数据时提示python27.dll缺失问题解决方法:在系统环境变量中的path添加D:\Program Files\PostgreSQL\10\pgAdmin 4\bin;重新启动电脑,就可以正常restore数据库了..._pg数据库恢复时缺失python7.dll
Android开发工具类_android snapshotwithoutstatusbar-程序员宅基地
文章浏览阅读314次。 BankCheck:银行卡管理 checkBankCard : 校验银行卡卡号是否合法 getBankCardCheckCode: 从不含校验位的银行卡卡号采用 Luhm 校验算法获得校验位 getNameOfBank : 通过银行卡的前六位确定判断银行开户行及卡种AppSharePreferenceMgr:SharePreference缓存数据 &nbs..._android snapshotwithoutstatusbar
机器学习——python训练CNN模型实战(傻瓜式教学,小学生都可以学会)代码开源_python如何训练cnn网络-程序员宅基地
文章浏览阅读2k次,点赞4次,收藏38次。在本例中,我们定义了一个包含三个卷积层和两个全连接层的 CNN 模型,以处理 3 通道的 32x32 图像。- 加载数据集:使用以下代码来加载 CIFAR10 数据集。第五章 python训练贝叶斯分类器模型实战。第三章 python训练神经网络模型实战。第二章 python训练决策树模型实战。第八章 python训练KNN模型实战。第九章 python训练CNN模型实战。第十章 python训练RNN模型实战。第一章 python训练线性模型实战。第七章 python训练聚类模型实战。_python如何训练cnn网络
Python : 批量替换代码文件内容,批量移动/覆盖文件_自动更换代码-程序员宅基地
文章浏览阅读2.4w次,点赞6次,收藏20次。Python : 批量自动替换代码文件内容,批量移动/覆盖代码文件使用背景代码解析 - getCppHppFileList代码解析 - replace_StrInFile代码解析 - reName_File代码解析 -Tkinter 图形界面,完整代码使用背景在设备端GUI页面显示上,很多是通过GUI上位机软件自动生成代码,然后把生成的代码copy到开发工程中编译使用。但由于种种原因,存在生成的代码与实际工程有些不兼容的情况,则生成的代码不能直接copy使用,我这遇到的是每次都需要改动一部分代码及文_自动更换代码
使用小程序云开发添加背景音乐_小储云怎么添加音乐播放-程序员宅基地
文章浏览阅读4.4k次,点赞2次,收藏31次。使用小程序云开发添加背景音乐且实现后台播放在网上看了很多种方法,有一些对浏览器有一定的要求,于是懒癌患者想出了另一种办法首先,要在小程序里添加音频,需要在js里写一段代码:(此方法来自微信官方https://developers.weixin.qq.com/miniprogram/dev/api/media/background-audio/BackgroundAudioManager.ht..._小储云怎么添加音乐播放