Neo4j入门_neo4j入门教程-程序员宅基地
1. 安装
- 从neo4j官网下载需要的desktop社区版本(免费),windows/osx/linux,下载之前需要注册登记个人信息,之后会给出激活码,用于后续安装过程中软件的激活。
- 具体的安装步骤,官网也给出了,个人用的osx版本。
- 下载完成之后,选择激活码的方式进行软件环境加载,如下图。
- 加载完成之后的页面。
2. 导入CSV数据
以下内容翻译自官方教程
根据数据量的大小,有三种方式导入方式,不同方式的标准和功能也不一样:
LOAD CSVCypher command:适合小于千万级的数据量;neo4j-adminbulk import tool:适合加载大规模的数据集;- Kettle import tool:超大规模的数据可以采用这种方式,包含数据流的映射和执行步骤,当然也要非常熟悉这个工具。
1. LOAD CSV
NEO4j图数据库使用Cypher语句作为查询和操作语句,类似于SQL语句。在Cypher语句使用手册里面,专门有一页讲load csv命令的,地址。这里只是粗略地介绍个人使用过程,参考教程【从桌面导入CSV文件】,依旧给出地址。
选择LOAD方式加载CSV文件,文件需要具有以下特征:
- 字符编码格式是utf-8;
- 最后一行的结束标志是系统默认的,unix: ‘\n’; windows: ‘\r\n’;
- 元素分割符号是’,’;
- 可以使用
FIELDTERMINATOR更改元素分隔符; - 字符串引用格式,但是读数据的时候,引用符号会被扔掉;
- 字符用双引号引用;
- 如果
dbms.import.csv.legacy_quote_escaping设置为默认值或者true,\会被当作转义字符; - 双引号必须在带引号的字符串中并使用转义字符或第二个双引号进行转义。
提供两种加载方式供参考:
- 如果将文件load到neo4j操作台上面,可以copy file path,进行CSV的加载。
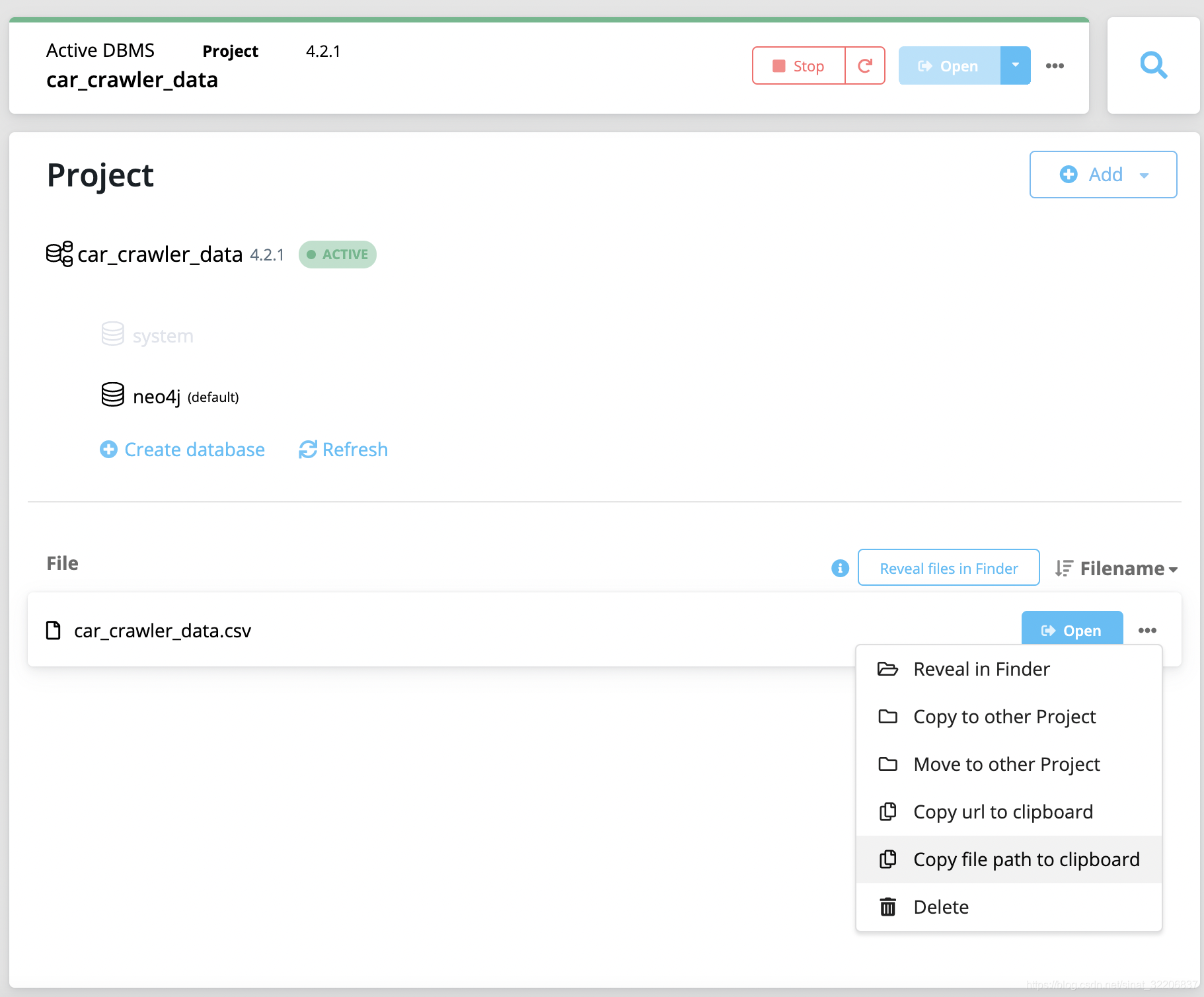
LOAD CSV FROM "http://localhost:11001/project-d04898ce-8135-42b8-8a18-17521bb9a198/car_crawler_data.csv" As row
return row
-
从桌面直接导入,与教程【从桌面导入CSV文件】的操作方法一致
打开新建数据库的settings文件,
dbms.directories.import=import默认导入数据的文件夹是import,因此将需要导入的数据拖入该文件夹就可以使用如下命令,加载CSV文件。
LOAD CSV FROM "file:///car_crawler_data.csv" AS row
return row
3. 创建图结构
load完之后的数据是不具备图结构的,需要创建图的节点和边。
1. 清空图层
MATCH (n) DETACH DELETE n; # 删除所有的节点和关系
2. 创建所有的节点,只给一个例子
LOAD CSV WITH HEADERS FROM 'file:///car_crawler.csv' AS row
WITH row.branch_name AS branch_name, row.xx AS xx
MERGE (b: branch {branch_name:branch_name})
SET b.xx = xx
return count(b);
加载crawler文件,该文件带有header,因此语句中需要包含with headers,计数时会忽略掉header行。
AS row: 给每一行起一个row的别名,类似于dataframe的iterrows()函数
WITH: 可以借鉴sql里面select,对row里面的数据进行挑选。
MERGE:可以用来创建节点和关系,这里创建了名字为branch节点,并用branch_name作为区分节点的key值,相当于sql里面的主键。b是标识符,没有实际意义的样子。
SET:可以给节点添加更多的属性,但不再是主键。
最后生成节点的样子如下:
MATCH是匹配的意思,可以做展示使用,从节点里面挑选branch,展示25个。
3. 创建关系
LOAD CSV WITH HEADERS FROM 'file:///car_crawler.csv' As row
WITH row.car_id AS car_id, row.branch_name AS branch_name
MATCH (c:car {car_id:car_id})
MATCH (b:branch {branch_name:branch_name})
MERGE (c)-[rel:belongs_to]->(b)
return count(rel);
先通过MATCH找到图中对应的节点
MERGE: 建立car和branch之间的关系,可以是有向,这里由c->b,也可以是无向的,去掉短横线后的箭头即可。
[]:中括号里面放置关系名称,在图中会显示在连接线上,如下图。

4. python链接neo4j
-
安装neo4j驱动
pip install neo4j -
官方给的参考代码如下,只包含
read_transaction, 还有一种write_transaction在下面实例中。
from neo4j import GraphDatabase
class HelloWorldExample:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self.driver.close()
def print_greeting(self, message):
with self.driver.session() as session:
greeting = session.write_transaction(self._create_and_return_greeting, message)
print(greeting)
@staticmethod
def _create_and_return_greeting(tx, message):
result = tx.run("CREATE (a:Greeting) "
"SET a.message = $message "
"RETURN a.message + ', from node ' + id(a)", message=message)
return result.single()[0]
if __name__ == "__main__":
greeter = HelloWorldExample("bolt://localhost:7687", "neo4j", "password")
greeter.print_greeting("hello, world")
greeter.close()
read_transaction实例
@staticmethod
def query_attributes_of_object(tx, object_type):
"""e.g 查询“汽车有哪些性能参数”, 返回一个list
"""
for item in tx.run("MATCH (c) where c.car_series = $car_series return c", car_series = object_type):
result = item["c"]
return result
def get_attributes_of_object(self, object_type: Text) -> List[Text]:
"""
Returns a list of all attributes that belong to the provided object type.
Args:
object_type: the object type
Returns: list of attributes of object_type
"""
with self.conn.session() as session:
ret = session.read_transaction(self.query_attributes_of_object, object_type)
return ret
参考
[1] neo4j cypher manual
[2] neo4j operations manual
[3] neo4j developer guides
[4] 手把手教你快速入门知识图谱 - Neo4J教程
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法