论文代码阅读及部分复现:Revisiting Deep Learning Models for Tabular Data-程序员宅基地
论文地址:https://arxiv.org/pdf/2106.11959.pdf
相关数据:https://www.dropbox.com/s/o53umyg6mn3zhxy/
2024年2月11日补充:
此处的LassoNet模型实际上只是带skip层MLP;实际的LassoNet作特征筛选时还需要更新lambda等值,耗时较长,此处仅取了中间的循环。
一、论文概述
现有的关于表格数据做深度学习的模型层出不穷,但是作者认为,由于在真实使用模型时有着不同的基准以及实验场合,这些提出的模型没有被很好地比较。因此,论文作者在论文中对各类模型进行了综述,并且自身提出了一个对Transformer作简单改进的模型:FT-Transformer,最终将ResNet-like类模型、Transformer-like类模型以及其他MLP模型在不同的数据集上训练、对比效果,最终确定了一个较好的衡量针对表格数据的深度学习模型的标准(bennchmark)。但是和梯度提升的决策树模型相比,还没有很好的基于深度学习的模型。
二、使用到的模型
1、MLP:也就是最常见的多层感知器,使用Relu激活函数与Dropout层
2、ResNet:残差神经网络,由残差块(ResNetBlock)组成,残差块可以理解为以下函数: 其中
3、FT-Transformer:这是论文作者提出的一个Transformer的简单变种,简而言之就是在传入Transformer之前加了一个Feature Tokenizer:将连续变量作线性变换,离散变量作Embedding,最后再加入一个CLS向量作为结果向量;将处理完的数据传入一个Encoder-only的Transformer中。
4、SNN:自归一化神经网络(注意不是“脉冲神经网络”),在原本的MLP模型基础上使用了SELU激活函数,能够训练更深的模型。
5、NODE:Neural oblivious decision ensembles,在神经网络中加入了决策树原理
6、TabNet:和NODE一样,也是在神经网络中加入了决策树原理
7、GrowNet:在神经网络中加入Boosting的思想
8、DCN:在Wide and Deep上改进,将线性模型部分换成Cross Network。在Cross Network中,每一层的输出都会乘以原始的输入特征。这个模型也是统一输入使用Embedding处理离散特征。
9、AutoInt:认为浅层模型收到交叉阶数限制,且DNN在高阶隐性交叉结果不好;这个模型加入了注意力机制。模型在输入时,会同时将离散特征与连续特征进行Embedding,将其分为三个矩阵:Query,Key,Values 将Query与Key作内积衡量相似度,使用Softmax得到attention,最终将Attention乘以values,得到一个head的结果。
10、CatBoost:使用了Ordered Target Statistics来处理多分类变量,避免了多分类变量作One-hot处理会产生维数爆炸的问题。
11、XGBoost:对损失函数进行了二阶泰勒展开,从而可以在训练时使用二阶导。随着版本迭代,现在的XGBoost也可以处理多分类变量了。
三、实验策略
首先,实验对每个模型在每个数据集上都使用了相同的预处理,大多数数据都是用了分位数转换处理,而数据集Helena和ALOI则使用了标准化(standard),Epsilon没有使用任何预处理。对于回归任务,所有的应变量都被做了标准化。
而对于每个模型,首先会使用Optuna作贝叶斯回归在验证集上调优获得一个“最优”的超参数,然后使用15个不同的随机数种子在,将这15个模型分成3组,每组平均单个预测模型。
调优流程
论文作者将所有调优的过程放到了tune.py这一个文件中,想要调优时只要运行这一个文件然后加上要调优的配置文件(toml)就可以了,github上的例子就是:
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml以tf-transformer的toml配置文件为例:
program = 'bin/ft_transformer.py'
[base_config]
seed = 0
[base_config.data]
normalization = 'quantile'
path = 'data/california_housing'
y_policy = 'mean_std'
[base_config.model]
activation = 'reglu'
initialization = 'kaiming'
n_heads = 8
prenormalization = true
[base_config.training]
batch_size = 256
eval_batch_size = 8192
n_epochs = 1000000000
optimizer = 'adamw'
patience = 16
[optimization.options]
n_trials = 100
[optimization.sampler]
seed = 0
[optimization.space.model]
attention_dropout = [ 'uniform', 0.0, 0.5 ]
d_ffn_factor = [ '$d_ffn_factor', 1.0, 4.0 ]
d_token = [ '$d_token', 64, 512 ]
ffn_dropout = [ 'uniform', 0.0, 0.5 ]
n_layers = [ 'int', 1, 4 ]
residual_dropout = [ '?uniform', 0.0, 0.0, 0.2 ]
[optimization.space.training]
lr = [ 'loguniform', 1e-05, 0.001 ]
weight_decay = [ 'loguniform', 1e-06, 0.001 ]
其中,program表明模型定义以及训练函数定义的位置,base_config是在训练对应数据集的固定参数,里面包含有以下信息:
seed:模型训练的随机数种子
data:记录了一切对数据进行的预处理,如正则化,数据路径以及y值预处理操作
model:记录了模型固定的参数,通常是决定模型本身结构与深度的参数,这部分参数不会作调优
training:记录了使用模型作训练以及验证时的参数,如batch_size,epoch数量、优化器以及patience等。这里的patience指的是又连续多少个epoch在验证集上没有改进后才会停止训练。
optimization:使用Optuna调优时的所用到的参数,其中options与sampler是作贝叶斯回归时的参数以及抽样参数,space.model是模型的参数空间,Optuna会在这些参数中找到最优的组合,space.training是训练时的参数,如学习率/权重衰减等,也是Optuna所要进行抽样选取最优解的对象。
读取toml格式的文件会转化为字典。

下面是实验调优的代码。
program = lib.get_path(args['program'])
program_copy = program.with_name(
program.stem + '___' + str(uuid.uuid4()).replace('-', '') + program.suffix
)
shutil.copyfile(program, program_copy)
atexit.register(lambda: program_copy.unlink())
checkpoint_path = output / 'checkpoint.pt'
if checkpoint_path.exists():
checkpoint = torch.load(checkpoint_path)
trial_configs, trial_stats, study, stats, timer = (
checkpoint['trial_configs'],
checkpoint['trial_stats'],
checkpoint['study'],
checkpoint['stats'],
checkpoint['timer'],
)
zero.set_random_state(checkpoint['random_state'])
if 'n_trials' in args['optimization']['options']:
args['optimization']['options']['n_trials'] -= len(study.trials)
if 'timeout' in args['optimization']['options']:
args['optimization']['options']['timeout'] -= timer()
stats.setdefault('continuations', []).append(len(study.trials))
print(f'Loading checkpoint ({len(study.trials)})')
else:
stats = lib.load_json(output / 'stats.json')
trial_configs = []
trial_stats = []
timer = zero.Timer()
study = optuna.create_study(
direction='maximize',
sampler=optuna.samplers.TPESampler(**args['optimization']['sampler']),
)
timer.run()
# ignore the progress bar warning
warnings.filterwarnings('ignore', category=optuna.exceptions.ExperimentalWarning)
study.optimize(
objective,
**args['optimization']['options'],
callbacks=[save_checkpoint],
show_progress_bar=True,
)
best_trial_id = study.best_trial.number
lib.dump_toml(trial_configs[best_trial_id], output / 'best.toml')
stats['best_stats'] = trial_stats[best_trial_id]
stats['time'] = lib.format_seconds(timer())
lib.dump_stats(stats, output, True)
lib.backup_output(output)首先程序会临时拷贝一份模型的定义文件,等到进程结束之后删除。此处的目的我估计是为了避免有多个进程访问同一个py文件。
之后开始检查有没有checkpoint,如果有checkpoint的话,会在checkpoint的基础上继续做调优,减去原本已经做完的的trial个数,否则的话就从头开始进行调优。
之后开始运行study.optimize函数,开始进行调优,其中objective对象就是我们定义的要调优的对象。
def sample_parameters(
trial: optuna.trial.Trial,
space: ty.Dict[str, ty.Any],
base_config: ty.Dict[str, ty.Any],
) -> ty.Dict[str, ty.Any]:
def get_distribution(distribution_name):
return getattr(trial, f'suggest_{distribution_name}')
result = {}
for label, subspace in space.items():
if isinstance(subspace, dict):
result[label] = sample_parameters(trial, subspace, base_config)
else:
assert isinstance(subspace, list)
distribution, *args = subspace
if distribution.startswith('?'):
default_value = args[0]
result[label] = (
get_distribution(distribution.lstrip('?'))(label, *args[1:])
if trial.suggest_categorical(f'optional_{label}', [False, True])
else default_value
)
elif distribution == '$mlp_d_layers':
min_n_layers, max_n_layers, d_min, d_max = args
n_layers = trial.suggest_int('n_layers', min_n_layers, max_n_layers)
suggest_dim = lambda name: trial.suggest_int(name, d_min, d_max) # noqa
d_first = [suggest_dim('d_first')] if n_layers else []
d_middle = (
[suggest_dim('d_middle')] * (n_layers - 2) if n_layers > 2 else []
)
d_last = [suggest_dim('d_last')] if n_layers > 1 else []
result[label] = d_first + d_middle + d_last
elif distribution == '$d_token':
assert len(args) == 2
try:
n_heads = base_config['model']['n_heads']
except KeyError:
n_heads = base_config['model']['n_latent_heads']
for x in args:
assert x % n_heads == 0
result[label] = trial.suggest_int('d_token', *args, n_heads) # type: ignore[code]
elif distribution in ['$d_ffn_factor', '$d_hidden_factor']:
if base_config['model']['activation'].endswith('glu'):
args = (args[0] * 2 / 3, args[1] * 2 / 3)
result[label] = trial.suggest_uniform('d_ffn_factor', *args)
else:
result[label] = get_distribution(distribution)(label, *args)
return result
def merge_sampled_parameters(config, sampled_parameters):
for k, v in sampled_parameters.items():
if isinstance(v, dict):
merge_sampled_parameters(config.setdefault(k, {}), v)
else:
assert k not in config
config[k] = v
def objective(trial: optuna.trial.Trial) -> float:
config = deepcopy(args['base_config'])
merge_sampled_parameters(
config, sample_parameters(trial, args['optimization']['space'], config)
)
if args.get('config_type') in ['trv2', 'trv4']:
config['model']['d_token'] -= (
config['model']['d_token'] % config['model']['n_heads']
)
if args.get('config_type') == 'trv4':
if config['model']['activation'].endswith('glu'):
# This adjustment is needed to keep the number of parameters roughly in the
# same range as for non-glu activations
config['model']['d_ffn_factor'] *= 2 / 3
trial_configs.append(config)
with tempfile.TemporaryDirectory() as dir_:
dir_ = Path(dir_)
out = dir_ / f'trial_{trial.number}'
config_path = out.with_suffix('.toml')
lib.dump_toml(config, config_path)
python = Path('/miniconda3/envs/main/bin/python')
subprocess.run(
[
str(python) if python.exists() else "python",
str(program_copy),
str(config_path),
],
check=True,
) #训练 subprocess.run可以取得返回结果等信息
stats = lib.load_json(out / 'stats.json')
stats['algorithm'] = stats['algorithm'].rsplit('___', 1)[0]
trial_stats.append(
{
**stats,
'trial_id': trial.number,
'tuning_time': lib.format_seconds(timer()),
}
)
lib.dump_json(trial_stats, output / 'trial_stats.json', indent=4)
lib.backup_output(output)
print(f'Time: {lib.format_seconds(timer())}')
return stats['metrics'][lib.VAL]['score']trv2和trv4在这个项目中没有用到,应该是论文作者的团队在别的项目中用到的参数。
首先使用sample_parameters函数将toml中的那些参数空间转化为Optuna中trial的属性。注意suggest_uniform在Optuna3.0版本开始传入参数不再支持单个*args了,所以最后2个分支需要改为:
result[label] = trial.suggest_float('d_ffn_factor', args[0], args[1])#trial.suggest_uniform('d_ffn_factor', *args)
else:
if distribution == "uniform":
result[label] = trial.suggest_float(label,args[0], args[1])
else:
result[label] = get_distribution(distribution)(label, *args)
return result最终转换为trial中的需要调优的参数:
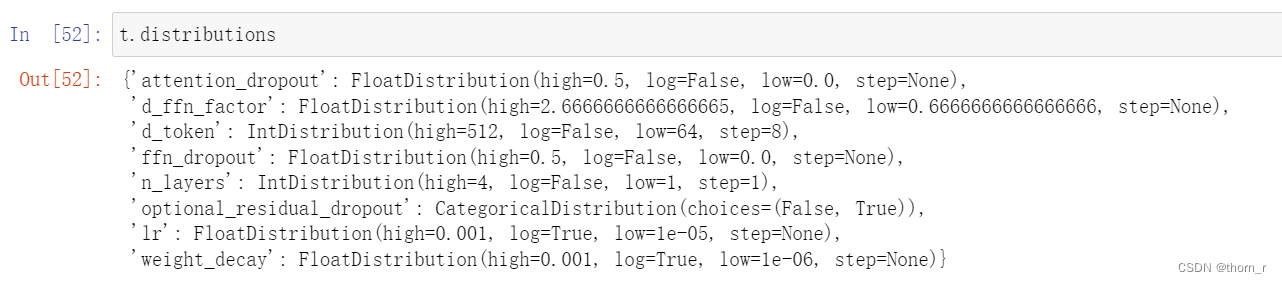
再使用merge_sampled_parameters将所有的参数放在一个config字典变量中,最后使用subprocess.run函数,将config对象传入模型定义的py文件进行训练,将结果保存并返回。这样,就能构建出用于Optuna优化的objective函数了。
注意此处某些参数的空间会有特殊处理:
如果参数在toml文件中标了"?",如dropout = [ '?uniform', 0.0, 0.0, 0.5 ],就意味着这个参数是“可选调优项”。此处的dropout的配置的含义是:首先在“要不要对这个参数调优”这个样本空间里进行抽样,如果不要调优的话,就分配其默认值0。如果要调优的话,就在后面0~0.5的均匀分布中抽样。
而对于$mlp_d_layers的特殊参数空间而言,会对以下4个部分进行参数空间的创建:需要多少层中间层,第一层,最后一层以及中间层分别要多大。
对于$d_token参数,通常是在Transformer-like的模型中,故而会检测其能否被注意力头数(n_head)整除。
剩下$d_ffn_factor和$d_hidden_factor这2个参数,当使用glu系的激活函数时,会进行特殊处理(除以3)。
下面纤细讲解一下数据预处理流程以及模型训练流程。
数据预处理流程
首先会创建一个数据集对象,读取数据文件中的npy文件。
@dc.dataclass
class Dataset:
N: ty.Optional[ArrayDict]
C: ty.Optional[ArrayDict]
y: ArrayDict
info: ty.Dict[str, ty.Any]
folder: ty.Optional[Path]
@classmethod
def from_dir(cls, dir_: ty.Union[Path, str]) -> 'Dataset':
dir_ = Path(dir_)
def load(item) -> ArrayDict:
return {
x: ty.cast(np.ndarray, np.load(dir_ / f'{item}_{x}.npy')) # type: ignore[code]
for x in ['train', 'val', 'test']
}
return Dataset(
load('N') if dir_.joinpath('N_train.npy').exists() else None,
load('C') if dir_.joinpath('C_train.npy').exists() else None,
load('y'),
util.load_json(dir_ / 'info.json'),
dir_,
)
其中,C是离散类变量,N是连续型变量,Y是因变量。 之后,分别对X和Y进行数据预处理。
def normalize(
X: ArrayDict, normalization: str, seed: int, noise: float = 1e-3
) -> ArrayDict:
X_train = X['train'].copy()
if normalization == 'standard':
normalizer = sklearn.preprocessing.StandardScaler()
elif normalization == 'quantile':
normalizer = sklearn.preprocessing.QuantileTransformer(
output_distribution='normal',
n_quantiles=max(min(X['train'].shape[0] // 30, 1000), 10),
subsample=1e9,
random_state=seed,
)
if noise:
stds = np.std(X_train, axis=0, keepdims=True)
noise_std = noise / np.maximum(stds, noise) # type: ignore[code]
X_train += noise_std * np.random.default_rng(seed).standard_normal( # type: ignore[code]
X_train.shape
)
else:
util.raise_unknown('normalization', normalization)
normalizer.fit(X_train)
return {k: normalizer.transform(v) for k, v in X.items()} # type: ignore[code]
def build_X(
self,
*,
normalization: ty.Optional[str],
num_nan_policy: str,
cat_nan_policy: str,
cat_policy: str,
cat_min_frequency: float = 0.0,
seed: int,
) -> ty.Union[ArrayDict, ty.Tuple[ArrayDict, ArrayDict]]:
cache_path = (
self.folder
/ f'build_X__{normalization}__{num_nan_policy}__{cat_nan_policy}__{cat_policy}__{seed}.pickle' # noqa
if self.folder
else None
)
if cache_path and cat_min_frequency:
cache_path = cache_path.with_name(
cache_path.name.replace('.pickle', f'__{cat_min_frequency}.pickle')
)
if cache_path and cache_path.exists():
print(f'Using cached X: {cache_path}')
with open(cache_path, 'rb') as f:
return pickle.load(f)
def save_result(x):
if cache_path:
with open(cache_path, 'wb') as f:
pickle.dump(x, f)
if self.N:
N = deepcopy(self.N)
num_nan_masks = {k: np.isnan(v) for k, v in N.items()}
if any(x.any() for x in num_nan_masks.values()): # type: ignore[code]
if num_nan_policy == 'mean':
num_new_values = np.nanmean(self.N['train'], axis=0)
else:
util.raise_unknown('numerical NaN policy', num_nan_policy)
for k, v in N.items():
num_nan_indices = np.where(num_nan_masks[k])
v[num_nan_indices] = np.take(num_new_values, num_nan_indices[1])
if normalization:
N = normalize(N, normalization, seed)
else:
N = None
if cat_policy == 'drop' or not self.C:
assert N is not None
save_result(N)
return N
C = deepcopy(self.C)
cat_nan_masks = {k: v == 'nan' for k, v in C.items()}
if any(x.any() for x in cat_nan_masks.values()): # type: ignore[code]
if cat_nan_policy == 'new':
cat_new_value = '___null___'
imputer = None
elif cat_nan_policy == 'most_frequent':
cat_new_value = None
imputer = SimpleImputer(strategy=cat_nan_policy) # type: ignore[code]
imputer.fit(C['train'])
else:
util.raise_unknown('categorical NaN policy', cat_nan_policy)
if imputer:
C = {k: imputer.transform(v) for k, v in C.items()}
else:
for k, v in C.items():
cat_nan_indices = np.where(cat_nan_masks[k])
v[cat_nan_indices] = cat_new_value
if cat_min_frequency:
C = ty.cast(ArrayDict, C)
min_count = round(len(C['train']) * cat_min_frequency)
rare_value = '___rare___'
C_new = {x: [] for x in C}
for column_idx in range(C['train'].shape[1]):
counter = Counter(C['train'][:, column_idx].tolist())
popular_categories = {k for k, v in counter.items() if v >= min_count}
for part in C_new:
C_new[part].append(
[
(x if x in popular_categories else rare_value)
for x in C[part][:, column_idx].tolist()
]
)
C = {k: np.array(v).T for k, v in C_new.items()}
unknown_value = np.iinfo('int64').max - 3
encoder = sklearn.preprocessing.OrdinalEncoder(
handle_unknown='use_encoded_value', # type: ignore[code]
unknown_value=unknown_value, # type: ignore[code]
dtype='int64', # type: ignore[code]
).fit(C['train'])
C = {k: encoder.transform(v) for k, v in C.items()}
max_values = C['train'].max(axis=0)
for part in ['val', 'test']:
for column_idx in range(C[part].shape[1]):
C[part][C[part][:, column_idx] == unknown_value, column_idx] = (
max_values[column_idx] + 1
)
if cat_policy == 'indices':
result = (N, C)
elif cat_policy == 'ohe':
ohe = sklearn.preprocessing.OneHotEncoder(
handle_unknown='ignore', sparse=False, dtype='float32' # type: ignore[code]
)
ohe.fit(C['train'])
C = {k: ohe.transform(v) for k, v in C.items()}
result = C if N is None else {x: np.hstack((N[x], C[x])) for x in N}
elif cat_policy == 'counter':
assert seed is not None
loo = LeaveOneOutEncoder(sigma=0.1, random_state=seed, return_df=False)
loo.fit(C['train'], self.y['train'])
C = {k: loo.transform(v).astype('float32') for k, v in C.items()} # type: ignore[code]
if not isinstance(C['train'], np.ndarray):
C = {k: v.values for k, v in C.items()} # type: ignore[code]
if normalization:
C = normalize(C, normalization, seed, inplace=True) # type: ignore[code]
result = C if N is None else {x: np.hstack((N[x], C[x])) for x in N}
else:
util.raise_unknown('categorical policy', cat_policy)
save_result(result)
return result # type: ignore[code]
在最前面的那个cache_path是用来储存相同处理参数下预处理过后的自变量的,在使用相同参数时可以直接拉取出来不用再做一遍预处理过程。之后分别对连续型变量和离散型变量作预处理:先做缺失值填充,再作数据标准化。连续变量的缺失值填充只有平均值填充一个策略,而对于离散型变量,缺失值有2个处理策略:一种是当做一个新的类别作为处理,另外一种则是使用对应特征中种类最多的类别进行填充。还有就是有一个cat_min_frequency参数,可以指定将出现低于cat_min_frequency频率的那些类别进行合并作为'___rare___'类。之后使用OrdinalEncoder将类别变量转换为数字。最后还有个cat_policy决定最终的输出结果:indices表示直接使用类别变量对应的index,one代表使用One-hotEncoder来处理类别变量,而counter则代表使用LeaveOneOutEncoder:将对应行的因变量排除后,其他对应这一类别的特征变量的均值作encoder。
def build_y(
self, policy: ty.Optional[str]
) -> ty.Tuple[ArrayDict, ty.Optional[ty.Dict[str, ty.Any]]]:
if self.is_regression:
assert policy == 'mean_std'
y = deepcopy(self.y)
if policy:
if not self.is_regression:
warnings.warn('y_policy is not None, but the task is NOT regression')
info = None
elif policy == 'mean_std':
mean, std = self.y['train'].mean(), self.y['train'].std()
y = {k: (v - mean) / std for k, v in y.items()}
info = {'policy': policy, 'mean': mean, 'std': std}
else:
util.raise_unknown('y policy', policy)
else:
info = None
return y, info而对于y值的处理,连续变量用单纯地标准化(减去平均值除以方差),离散变量则不使用任何的处理方式(使用了会给出一个warning,而且离散变量作标准化实际上也没有意义)。
训练流程
此处以论文作者所作的FT-Transformer举例。
if __name__ == "__main__":
args, output = lib.load_config()
args['model'].setdefault('token_bias', True)
args['model'].setdefault('kv_compression', None)
args['model'].setdefault('kv_compression_sharing', None)
# %%
zero.set_randomness(args['seed'])
dataset_dir = lib.get_path(args['data']['path'])
stats: ty.Dict[str, ty.Any] = {
'dataset': dataset_dir.name,
'algorithm': Path(__file__).stem,
**lib.load_json(output / 'stats.json'), #**用以扩展字典,将另一个字典中的键值对传入
}
timer = zero.Timer()
timer.run()
D = lib.Dataset.from_dir(dataset_dir)
X = D.build_X(
normalization=args['data'].get('normalization'),
num_nan_policy='mean',
cat_nan_policy='new',
cat_policy=args['data'].get('cat_policy', 'indices'),
cat_min_frequency=args['data'].get('cat_min_frequency', 0.0),
seed=args['seed'],
)
if not isinstance(X, tuple):
X = (X, None)
zero.set_randomness(args['seed'])
Y, y_info = D.build_y(args['data'].get('y_policy'))
lib.dump_pickle(y_info, output / 'y_info.pickle')
X = tuple(None if x is None else lib.to_tensors(x) for x in X)
Y = lib.to_tensors(Y)
device = lib.get_device()
if device.type != 'cpu':
X = tuple(
None if x is None else {k: v.to(device) for k, v in x.items()} for x in X
)
Y_device = {k: v.to(device) for k, v in Y.items()}
else:
Y_device = Y
X_num, X_cat = X
del X
if not D.is_multiclass:
Y_device = {k: v.float() for k, v in Y_device.items()}
train_size = D.size(lib.TRAIN)
batch_size = args['training']['batch_size']
epoch_size = stats['epoch_size'] = math.ceil(train_size / batch_size)
eval_batch_size = args['training']['eval_batch_size']
chunk_size = None
loss_fn = (
F.binary_cross_entropy_with_logits
if D.is_binclass
else F.cross_entropy
if D.is_multiclass
else F.mse_loss
)
model = Transformer(
d_numerical=0 if X_num is None else X_num['train'].shape[1],
categories=lib.get_categories(X_cat),
d_out=D.info['n_classes'] if D.is_multiclass else 1,
**args['model'],
).to(device)
if torch.cuda.device_count() > 1: # type: ignore[code]
print('Using nn.DataParallel')
model = nn.DataParallel(model)
stats['n_parameters'] = lib.get_n_parameters(model)
def needs_wd(name):
return all(x not in name for x in ['tokenizer', '.norm', '.bias'])
for x in ['tokenizer', '.norm', '.bias']:
assert any(x in a for a in (b[0] for b in model.named_parameters()))
parameters_with_wd = [v for k, v in model.named_parameters() if needs_wd(k)]
parameters_without_wd = [v for k, v in model.named_parameters() if not needs_wd(k)]
optimizer = lib.make_optimizer(
args['training']['optimizer'],
(
[
{'params': parameters_with_wd},
{'params': parameters_without_wd, 'weight_decay': 0.0},
]
),
args['training']['lr'],
args['training']['weight_decay'],
)
stream = zero.Stream(lib.IndexLoader(train_size, batch_size, True, device))
progress = zero.ProgressTracker(args['training']['patience'])
training_log = {lib.TRAIN: [], lib.VAL: [], lib.TEST: []}
timer = zero.Timer()
checkpoint_path = output / 'checkpoint.pt'
def print_epoch_info():
print(f'\n>>> Epoch {stream.epoch} | {lib.format_seconds(timer())} | {output}')
print(
' | '.join(
f'{k} = {v}'
for k, v in {
'lr': lib.get_lr(optimizer),
'batch_size': batch_size,
'chunk_size': chunk_size,
'epoch_size': stats['epoch_size'],
'n_parameters': stats['n_parameters'],
}.items()
)
)
def apply_model(part, idx):
return model(
None if X_num is None else X_num[part][idx],
None if X_cat is None else X_cat[part][idx],
)
@torch.no_grad()
def evaluate(parts):
global eval_batch_size
model.eval()
metrics = {}
predictions = {}
for part in parts:
while eval_batch_size:
try:
predictions[part] = (
torch.cat(
[
apply_model(part, idx)
for idx in lib.IndexLoader(
D.size(part), eval_batch_size, False, device
)
]
)
.cpu()
.numpy()
)
except RuntimeError as err:
if not lib.is_oom_exception(err):
raise
eval_batch_size //= 2
print('New eval batch size:', eval_batch_size)
stats['eval_batch_size'] = eval_batch_size
else:
break
if not eval_batch_size:
RuntimeError('Not enough memory even for eval_batch_size=1')
metrics[part] = lib.calculate_metrics(
D.info['task_type'],
Y[part].numpy(), # type: ignore[code]
predictions[part], # type: ignore[code]
'logits',
y_info,
)
for part, part_metrics in metrics.items():
print(f'[{part:<5}]', lib.make_summary(part_metrics))
return metrics, predictions
def save_checkpoint(final):
torch.save(
{
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'stream': stream.state_dict(),
'random_state': zero.get_random_state(),
**{
x: globals()[x]
for x in [
'progress',
'stats',
'timer',
'training_log',
]
},
},
checkpoint_path,
)
lib.dump_stats(stats, output, final)
lib.backup_output(output)
# %%
timer.run()
for epoch in stream.epochs(args['training']['n_epochs']):
print_epoch_info()
model.train()
epoch_losses = []
for batch_idx in epoch:
loss, new_chunk_size = lib.train_with_auto_virtual_batch( #一次训练的代码
optimizer,
loss_fn,
lambda x: (apply_model(lib.TRAIN, x), Y_device[lib.TRAIN][x]),
batch_idx,
chunk_size or batch_size,
)
epoch_losses.append(loss.detach())
if new_chunk_size and new_chunk_size < (chunk_size or batch_size):
stats['chunk_size'] = chunk_size = new_chunk_size
print('New chunk size:', chunk_size)
epoch_losses = torch.stack(epoch_losses).tolist()
training_log[lib.TRAIN].extend(epoch_losses)
print(f'[{lib.TRAIN}] loss = {round(sum(epoch_losses) / len(epoch_losses), 3)}')
metrics, predictions = evaluate([lib.VAL, lib.TEST])
for k, v in metrics.items():
training_log[k].append(v)
progress.update(metrics[lib.VAL]['score'])
if progress.success:
print('New best epoch!')
stats['best_epoch'] = stream.epoch
stats['metrics'] = metrics
save_checkpoint(False)
for k, v in predictions.items():
np.save(output / f'p_{k}.npy', v)
elif progress.fail:
break
# %%
print('\nRunning the final evaluation...')
model.load_state_dict(torch.load(checkpoint_path)['model'])
stats['metrics'], predictions = evaluate(lib.PARTS)
for k, v in predictions.items():
np.save(output / f'p_{k}.npy', v)
stats['time'] = lib.format_seconds(timer())
save_checkpoint(True)
print('Done!')
首先使用定义在util.py中的load_config函数将命令行中传入的toml文件读入进来,然后生成一个stats.json文件,之后使用data.py中的方法构造并预处理X和Y。之后除了定义在每个py文件中的模型架构外,还会有用一些共有方法对模型训练进行汇总:
对于优化器,会使用一个make_optimizer方法来构建,其中对于特定的参数会加入权重衰减从策略weight_decay。
作者使用了libzero包中的Stream方法来维护每个epoch与batch_size的循环。这个Stream的作用就是能够随时存储与回复循环中的状态并自定义epoch。同时使用这个包下的ProgressTracker来设定模型的early stop。当16个epoch后验证集上依然没有改进时,进入progress.fail分支提前结束训练。
对于训练部分,作者构造了train_with_auto_virtual_batch函数,此处的chunk_size当一个batch的size对内存而言过大时,会更新成原本的1/2
def train_with_auto_virtual_batch(
optimizer,
loss_fn,
step,
batch,
chunk_size: int,
) -> ty.Tuple[Tensor, int]:
batch_size = len(batch)
random_state = zero.get_random_state()
while chunk_size != 0:
try:
zero.set_random_state(random_state)
optimizer.zero_grad()
if batch_size <= chunk_size:
loss = loss_fn(*step(batch))
loss.backward()
else:
loss = None
for chunk in zero.iter_batches(batch, chunk_size):
chunk_loss = loss_fn(*step(chunk))
chunk_loss = chunk_loss * (len(chunk) / batch_size)
chunk_loss.backward()
if loss is None:
loss = chunk_loss.detach()
else:
loss += chunk_loss.detach()
except RuntimeError as err:
if not is_oom_exception(err):
raise
chunk_size //= 2
else:
break
if not chunk_size:
raise RuntimeError('Not enough memory even for batch_size=1')
optimizer.step()
return loss, chunk_size # type: ignore[code]
zero.get/set_random_state()可以全局地给numpy/torch/random赋予相同的随机数种子。注意这个方法在0.0.8版本中已经没有了,如果需要和代码一样调试的话记得按照requirements.txt中的版本:
pip install libzero==0.0.3.dev7zero.iter_batches的作用上和把数据放到DataLoader里面一样,但是zero这个包里说zero.iter_batches函数更好,因为它是基于batch的索引而非DataLoader那样的基于项的索引。
而对于CatBoost和XGBoost而言,由于fit函数已经有了,所以直接将toml的各个参数传入就可以了,唯一需要注意的就是XGBoost不会自动保存验证集上效果最好的模型,需要我们传入early_stop参数去控制。
四、部分实验内容复现
由于笔者本身的硬件资源有限,只针对Adult数据集选取了FT-Transformer,ResNet,LightGBM,XGBoost并使用作者给出的超参数进行实验。其中FT-Transformer同时在自己的电脑上进行了调优以作对比组。除此以外,还加入了LassoNet进行了调优以及作为对照组。实验的详细代码见第五部分。
各个模型结果:
| model | accuracy | recall |
| FT_Transformer | 0.859034048 | 0.646160513 |
| FT_Transformer自己调优的 | 0.860176484 | 0.609707055 |
| lassoNet | 0.856626333 | 0.593898423 |
| lightGBM | 0.86809983 | 0.645103137 |
| ResNet | 0.853411953 | 0.639781591 |
| xgboost | 0.87231333 | 0.640006934 |
从结果中可以看出,就准确率而言集成树模型(XGBoost和LightGBM)依旧要优于各个深度学习模型;而在各个深度学习模型中,作者给出的FT-Transformer成绩较优。此外,由于Adult数据集本身0-1的比例约为77:23;所以我还记录了各个模型对于正例(1)的召回率。从结果中可以看出,召回率依旧是集成树模型更高。尽管其中的FT-Transformer也已经和树模型的结果相近,但是由于准确率的差距更大,训练的时间更长耗能更多,故而不能说它比树模型的效果更好。
五、复现代码
尽管论文作者已经给出了实验代码,然而笔者的Linux系统似乎有些问题,Windows下的虚拟环境搭建也由于网络问题需要我花一段时间解决,故而在原来的代码上进行了稍微的修改。
FT-Transformer的超参数调优
#模型定义部分与上文一样,此处省略
#读取设定
import pytomlpp as toml
ArrayDict = ty.Dict[str, np.ndarray]
def normalize(
X, normalization,seed,noise=1e-3
):
X_train = X['train'].copy()
if normalization == 'standard':
normalizer = sklearn.preprocessing.StandardScaler()
elif normalization == 'quantile':
normalizer = sklearn.preprocessing.QuantileTransformer(
output_distribution='normal',
n_quantiles=max(min(X['train'].shape[0] // 30, 1000), 10),
subsample=int(1e9),
random_state=seed,
)
if noise:
stds = np.std(X_train, axis=0, keepdims=True)
noise_std = noise / np.maximum(stds, noise) # type: ignore[code]
X_train += noise_std * np.random.default_rng(seed).standard_normal( # type: ignore[code]
X_train.shape
)
else:
raise ValueError('Unknow normalization')
normalizer.fit(X_train)
return {k: normalizer.transform(v) for k, v in X.items()} # type: ignore[code]
class CustomDataset(Dataset):
def __init__(self,dir_,data_part,normalization,num_nan_policy,cat_nan_policy,
cat_policy,seed,
y_poicy=None,cat_min_frequency=0
):
super(CustomDataset,self).__init__()
dir_ = Path(dir_)
def load(item) -> ArrayDict:
return {
x: ty.cast(np.ndarray, np.load(dir_ / f'{item}_{x}.npy')) # type: ignore[code]
for x in ['train', 'val', 'test']
}
self.N = load('N') if dir_.joinpath('N_train.npy').exists() else None
self.C = load('C') if dir_.joinpath('C_train.npy').exists() else None
self.y = load('y')
self.info = json.loads((dir_ / 'info.json').read_text())
#pre-process
cache_path = f"build_dataset_{normalization}__{num_nan_policy}__{cat_nan_policy}__{cat_policy}__{seed}.pickle"
if cat_min_frequency>0:
cache_path = cache_path.replace('.pickle', f'__{cat_min_frequency}.pickle')
cache_path = Path(cache_path)
if cache_path.exists():
print("Using cache")
with open(cache_path, 'rb') as f:
data = pickle.load(f)
self.x = data
else:
def save_result(x):
if cache_path:
with open(cache_path, 'wb') as f:
pickle.dump(x, f)
if self.N:
N = deepcopy(self.N)
num_nan_masks = {k: np.isnan(v) for k, v in N.items()}
if any(x.any() for x in num_nan_masks.values()): # type: ignore[code]
if num_nan_policy == 'mean':
num_new_values = np.nanmean(self.N['train'], axis=0)
else:
raise ValueError('Unknown numerical NaN policy')
for k, v in N.items():
num_nan_indices = np.where(num_nan_masks[k])
v[num_nan_indices] = np.take(num_new_values, num_nan_indices[1])
if normalization:
N = normalize(N, normalization, seed)
else:
N = None
C = deepcopy(self.C)
cat_nan_masks = {k: v == 'nan' for k, v in C.items()}
if any(x.any() for x in cat_nan_masks.values()): # type: ignore[code]
if cat_nan_policy == 'new':
cat_new_value = '___null___'
imputer = None
elif cat_nan_policy == 'most_frequent':
cat_new_value = None
imputer = SimpleImputer(strategy=cat_nan_policy) # type: ignore[code]
imputer.fit(C['train'])
else:
raise ValueError('Unknown categorical NaN policy')
if imputer:
C = {k: imputer.transform(v) for k, v in C.items()}
else:
for k, v in C.items():
cat_nan_indices = np.where(cat_nan_masks[k])
v[cat_nan_indices] = cat_new_value
if cat_min_frequency:
C = ty.cast(ArrayDict, C)
min_count = round(len(C['train']) * cat_min_frequency)
rare_value = '___rare___'
C_new = {x: [] for x in C}
for column_idx in range(C['train'].shape[1]):
counter = Counter(C['train'][:, column_idx].tolist())
popular_categories = {k for k, v in counter.items() if v >= min_count}
for part in C_new:
C_new[part].append(
[
(x if x in popular_categories else rare_value)
for x in C[part][:, column_idx].tolist()
]
)
C = {k: np.array(v).T for k, v in C_new.items()}
unknown_value = np.iinfo('int64').max - 3
encoder = sklearn.preprocessing.OrdinalEncoder(
handle_unknown='use_encoded_value', # type: ignore[code]
unknown_value=unknown_value, # type: ignore[code]
dtype='int64', # type: ignore[code]
).fit(C['train'])
C = {k: encoder.transform(v) for k, v in C.items()}
max_values = C['train'].max(axis=0)
for part in ['val', 'test']:
for column_idx in range(C[part].shape[1]):
C[part][C[part][:, column_idx] == unknown_value, column_idx] = (
max_values[column_idx] + 1
)
if cat_policy == 'indices':
result = (N, C)
elif cat_policy == 'ohe':
ohe = sklearn.preprocessing.OneHotEncoder(
handle_unknown='ignore', sparse=False, dtype='float32' # type: ignore[code]
)
ohe.fit(C['train'])
C = {k: ohe.transform(v) for k, v in C.items()}
result = C if N is None else {x: np.hstack((N[x], C[x])) for x in N}
elif cat_policy == 'counter':
assert seed is not None
loo = LeaveOneOutEncoder(sigma=0.1, random_state=seed, return_df=False)
loo.fit(C['train'], self.y['train'])
C = {k: loo.transform(v).astype('float32') for k, v in C.items()} # type: ignore[code]
if not isinstance(C['train'], np.ndarray):
C = {k: v.values for k, v in C.items()} # type: ignore[code]
if normalization:
C = normalize(C, normalization, seed, inplace=True) # type: ignore[code]
result = C if N is None else {x: np.hstack((N[x], C[x])) for x in N}
else:
raise ValueError('Unknow categorical policy')
save_result(result)
self.x = result
self.X_num,self.X_cat = self.x
self.X_num = None if self.X_num is None else self.X_num[data_part]
self.X_cat = None if self.X_cat is None else self.X_cat[data_part]
# build Y
if self.info['task_type'] == 'regression':
assert policy == 'mean_std'
y = deepcopy(self.y)
if y_poicy:
if not self.info['task_type'] == 'regression':
warnings.warn('y_policy is not None, but the task is NOT regression')
info = None
elif y_poicy == 'mean_std':
mean, std = self.y['train'].mean(), self.y['train'].std()
y = {k: (v - mean) / std for k, v in y.items()}
info = {'policy': policy, 'mean': mean, 'std': std}
else:
raise ValueError('Unknow y policy')
else:
info = None
self.y = y[data_part]
if len(self.y.shape)==1:
self.y = self.y.reshape((self.y.shape[0],1))
self.y_info = info
def __len__(self):
X = self.X_num if self.X_num is not None else self.X_cat
return len(X)
def __getitem__(self,idx):
return torch.FloatTensor(self.X_num[idx]).to(device),torch.IntTensor(self.X_cat[idx]).to(device),torch.FloatTensor(self.y[idx]).to(device)
data_path_father = "D:/rtdl_data.tar/rtdl_data/data/"
configs = toml.load("D:/rtdl-revisiting-models-main/output/adult/ft_transformer/tuning/0.toml")
data_configs = configs["base_config"]["data"]
configs["base_config"]["model"].setdefault('token_bias', True)
configs["base_config"]["model"].setdefault('kv_compression', None)
configs["base_config"]["model"].setdefault('kv_compression_sharing', None)
D_train = CustomDataset(
data_path_father+"adult"
,data_part="train"
,normalization=data_configs["normalization"]
,num_nan_policy="mean"
,cat_nan_policy="new"
,cat_policy=data_configs.get("cat_policy", 'indices')
,seed=configs["base_config"]["seed"]
,y_poicy=data_configs.get("y_policy"),cat_min_frequency=0
)
D_valid = CustomDataset(
data_path_father+"adult"
,data_part="val"
,normalization=data_configs["normalization"]
,num_nan_policy="mean"
,cat_nan_policy="new"
,cat_policy=data_configs.get("cat_policy", 'indices')
,seed=configs["base_config"]["seed"]
,y_poicy=data_configs.get("y_policy"),cat_min_frequency=0
)
D_test = CustomDataset(
data_path_father+"adult"
,data_part="test"
,normalization=data_configs["normalization"]
,num_nan_policy="mean"
,cat_nan_policy="new"
,cat_policy=data_configs.get("cat_policy", 'indices')
,seed=configs["base_config"]["seed"]
,y_poicy=data_configs.get("y_policy"),cat_min_frequency=0
)
dl_train = DataLoader(D_train,batch_size=configs["base_config"]["training"]["batch_size"])
dl_val = DataLoader(D_valid,batch_size=len(D_valid))
dl_test = DataLoader(D_test,batch_size=len(D_test))
def make_optimizer(
optimizer: str,
parameter_groups,
lr: float,
weight_decay: float,
) -> optim.Optimizer:
Optimizer = {
'adam': optim.Adam,
'adamw': optim.AdamW,
'sgd': optim.SGD,
}[optimizer]
momentum = (0.9,) if Optimizer is optim.SGD else ()
return Optimizer(parameter_groups, lr, *momentum, weight_decay=weight_decay)
def needs_wd(name):
return all(x not in name for x in ['tokenizer', '.norm', '.bias'])
import optuna
def sample_parameters(trial,space,base_config):
def get_distribution(distribution_name):
return getattr(trial, f'suggest_{distribution_name}')
result = {}
for label, subspace in space.items():
if isinstance(subspace, dict):
result[label] = sample_parameters(trial, subspace, base_config)
else:
assert isinstance(subspace, list)
distribution, *args = subspace
if distribution.startswith('?'): #此处我个人的理解是:这个参数在原本的调试范围基础上还要增加一个"optional_"作取舍,可以理解为:先取舍是否使用默认值,然后在后面给定范围内作调优看看哪个更好。
default_value = args[0]
result[label] = (
get_distribution(distribution.lstrip('?'))(label, *args[1:])
if trial.suggest_categorical(f'optional_{label}', [False, True])
else default_value
)
elif distribution == '$mlp_d_layers': #格式特殊
min_n_layers, max_n_layers, d_min, d_max = args
n_layers = trial.suggest_int('n_layers', min_n_layers, max_n_layers)
suggest_dim = lambda name: trial.suggest_int(name, d_min, d_max) # noqa
d_first = [suggest_dim('d_first')] if n_layers else []
d_middle = (
[suggest_dim('d_middle')] * (n_layers - 2) if n_layers > 2 else []
)
d_last = [suggest_dim('d_last')] if n_layers > 1 else []
result[label] = d_first + d_middle + d_last
elif distribution == '$d_token':#多了一个检测的步骤
assert len(args) == 2
try:
n_heads = base_config['model']['n_heads']
except KeyError:
n_heads = base_config['model']['n_latent_heads']
for x in args:
assert x % n_heads == 0
result[label] = trial.suggest_int('d_token', *args, n_heads)# n_heads是步长,确保d_token能够被n_heads整除 # type: ignore[code]
elif distribution in ['$d_ffn_factor', '$d_hidden_factor']: #对于glu系激活函数这2个参数特殊处理特殊处理
if base_config['model']['activation'].endswith('glu'):
args = (args[0] * 2 / 3, args[1] * 2 / 3)
result[label] = trial.suggest_uniform('d_ffn_factor', *args)
else:
result[label] = get_distribution(distribution)(label, *args)
return result
def merge_sampled_parameters(config, sampled_parameters):
for k, v in sampled_parameters.items():
if isinstance(v, dict):
merge_sampled_parameters(config.setdefault(k, {}), v)
else:
assert k not in config
config[k] = v
def objective(trial):
config = deepcopy(configs['base_config'])
merge_sampled_parameters(
config, sample_parameters(trial, configs['optimization']['space'], config)
)
model = Transformer(
d_num=0 if D_train.X_num is None else D_train.X_num.shape[1],
categories = None if D_train.X_cat is None else [len(set(D_train.X_cat[:, i].tolist())) for i in range(D_train.X_cat.shape[1])],
d_out=D_train.info['n_classes'] if D_train.info["task_type"]=="multiclass" else 1
,**config['model']
).to(device)
parameters_with_wd = [v for k, v in model.named_parameters() if needs_wd(k)]
parameters_without_wd = [v for k, v in model.named_parameters() if not needs_wd(k)]
loss_fn = (
F.binary_cross_entropy_with_logits
if D_train.info["task_type"]=="binclass"
else F.cross_entropy
if D_train.info["task_type"]=="multiclass"
else F.mse_loss
)
optimizer = make_optimizer(
config["training"]["optimizer"],
(
[
{'params': parameters_with_wd},
{'params': parameters_without_wd, 'weight_decay': 0.0},
]
),
config["training"]["lr"],#to be trained in optuna
config["training"]["weight_decay"]#to be trained in optuna
)
loss_best = np.nan
best_epoch = -1
patience = 0
def save_state():
torch.save(
model.state_dict(),os.path.join(os.getcwd(),"ft_transformer_state.pickle")
)
with open(os.path.join(os.getcwd(),"best_state_ft_transformer.json"),"w") as f:
json.dump(config,f)
#dl_train.batch_size=config['training']['batch_size']
for epoch in range(config['training']['n_epochs']):
model.train()
for i,(x_num,x_cat,y) in enumerate(dl_train):
optimizer.zero_grad()
y_batch = model(x_num,x_cat)
loss = loss_fn(y_batch.reshape((y_batch.shape[0],1)),y)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
for i,(x_num,x_cat,y) in enumerate(dl_val): #只有1个迭代
y_batch = model(x_num,x_cat)
loss = loss_fn(y_batch.reshape((y_batch.shape[0],1)),y)
new_loss = loss.detach()
if np.isnan(loss_best) or new_loss.cpu().numpy() < loss_best:
patience = 0
best_epoch = epoch
loss_best = new_loss.cpu().numpy()
save_state()
else:
patience+=1
if patience>= config['training']['patience']:
break
return loss_best
study = optuna.create_study(
direction="minimize",
sampler=optuna.samplers.TPESampler(**configs['optimization']['sampler']),
)
study.optimize(
objective,
**configs['optimization']['options'],
#callbacks=[save_checkpoint],
show_progress_bar=True,
)LassoNet的模型定义与超参数调优
首先,定义toml文件:
[base_config]
seed = 0
[base_config.data]
normalization = 'quantile'
path = 'data/adult'
cat_policy = 'indices'
[base_config.model]
[base_config.training]
batch_size = 256
eval_batch_size = 8192
n_epochs = 1000000000
optimizer = 'adamw'
patience = 16
[optimization.options]
n_trials = 100
[optimization.sampler]
seed = 0
[optimization.space.model]
dims = [ '$mlp_d_layers', 1, 8, 1, 512 ]
d_embedding = ['int', 64, 512]
dropout = [ '?uniform', 0.0, 0.0, 0.5 ]
gamma = [ '?loguniform', 0, 1e-08, 100.0 ]
lambda_ = [ '?loguniform', 0, 1e-08, 100.0 ]
M = [ 'int', 10, 50 ]
gamma_skip = [ '?loguniform', 0, 1e-08, 100.0 ]
[optimization.space.training]
lr = [ 'loguniform', 1e-05, 0.01 ]
weight_decay = [ '?loguniform', 0.0, 1e-06, 0.001 ]
from itertools import islice
def soft_threshold(l, x):
return torch.sign(x) * torch.relu(torch.abs(x) - l)
def sign_binary(x):
ones = torch.ones_like(x)
return torch.where(x >= 0, ones, -ones)
def prox(v, u, *, lambda_, lambda_bar, M):
"""
v has shape (m,) or (m, batches)
u has shape (k,) or (k, batches)
supports GPU tensors
"""
onedim = len(v.shape) == 1
if onedim:
v = v.unsqueeze(-1)
u = u.unsqueeze(-1)
u_abs_sorted = torch.sort(u.abs(), dim=0, descending=True).values
k, batch = u.shape
s = torch.arange(k + 1.0).view(-1, 1).to(v)
zeros = torch.zeros(1, batch).to(u)
a_s = lambda_ - M * torch.cat(
[zeros, torch.cumsum(u_abs_sorted - lambda_bar, dim=0)]
)
norm_v = torch.norm(v, p=2, dim=0)
x = F.relu(1 - a_s / norm_v) / (1 + s * M ** 2)
w = M * x * norm_v
intervals = soft_threshold(lambda_bar, u_abs_sorted)
lower = torch.cat([intervals, zeros])
idx = torch.sum(lower > w, dim=0).unsqueeze(0)
x_star = torch.gather(x, 0, idx).view(1, batch)
w_star = torch.gather(w, 0, idx).view(1, batch)
beta_star = x_star * v
theta_star = sign_binary(u) * torch.min(soft_threshold(lambda_bar, u.abs()), w_star)
if onedim:
beta_star.squeeze_(-1)
theta_star.squeeze_(-1)
return beta_star, theta_star
def inplace_prox(beta, theta, lambda_, lambda_bar, M):
beta.weight.data, theta.weight.data = prox(
beta.weight.data, theta.weight.data, lambda_=lambda_, lambda_bar=lambda_bar, M=M
)
def inplace_group_prox(groups, beta, theta, lambda_, lambda_bar, M):
"""
groups is an iterable such that group[i] contains the indices of features in group i
"""
beta_ = beta.weight.data
theta_ = theta.weight.data
beta_ans = torch.empty_like(beta_)
theta_ans = torch.empty_like(theta_)
for g in groups:
group_beta = beta_[:, g]
group_beta_shape = group_beta.shape
group_theta = theta_[:, g]
group_theta_shape = group_theta.shape
group_beta, group_theta = prox(
group_beta.reshape(-1),
group_theta.reshape(-1),
lambda_=lambda_,
lambda_bar=lambda_bar,
M=M,
)
beta_ans[:, g] = group_beta.reshape(*group_beta_shape)
theta_ans[:, g] = group_theta.reshape(*group_theta_shape)
beta.weight.data, theta.weight.data = beta_ans, theta_ans
class LassoNet(nn.Module):
def __init__(self,d_numerical,categories,d_out,d_embedding, dims,gamma,gamma_skip,lambda_,M, groups=None, dropout=None):
"""
first dimension is input
last dimension is output
`groups` is a list of list such that `groups[i]`
contains the indices of the features in the i-th group
"""
#assert len(dims) > 2
if groups is not None:
n_inputs = dims[0]
all_indices = []
for g in groups:
for i in g:
all_indices.append(i)
assert len(all_indices) == n_inputs and set(all_indices) == set(
range(n_inputs)
), f"Groups must be a partition of range(n_inputs={n_inputs})"
self.groups = groups
super().__init__()
#加入numerical和categories的输入处理
d_in = d_numerical
if categories is not None:
d_in += len(categories) * d_embedding
category_offsets = torch.tensor([0] + categories[:-1]).cumsum(0)
self.register_buffer('category_offsets', category_offsets)
self.category_embeddings = nn.Embedding(sum(categories), d_embedding)
nn.init.kaiming_uniform_(self.category_embeddings.weight, a=math.sqrt(5))
print(f'{self.category_embeddings.weight.shape=}')
dims = [d_in]+dims+[d_out]
self.gamma = gamma
self.gamma_skip = gamma_skip
self.lambda_ = lambda_
self.M = M
# 新增部分结束
self.dropout = nn.Dropout(p=dropout) if dropout is not None else None
self.layers = nn.ModuleList(
[nn.Linear(dims[i], dims[i + 1]) for i in range(len(dims) - 1)]
)
self.skip = nn.Linear(dims[0], dims[-1], bias=False)
def forward(self, x_num,x_cat):
inp = []
if x_num is not None:
inp.append(x_num)
if x_cat is not None:
inp.append(
self.category_embeddings(x_cat + self.category_offsets[None]).view(
x_cat.size(0), -1
)
)
inp = torch.cat(inp, dim=-1)
current_layer = inp
result = self.skip(inp)
for theta in self.layers:
current_layer = theta(current_layer)
if theta is not self.layers[-1]:
if self.dropout is not None:
current_layer = self.dropout(current_layer)
current_layer = F.relu(current_layer)
return result + current_layer
def prox(self, *, lambda_, lambda_bar=0, M=1):
if self.groups is None:
with torch.no_grad():
inplace_prox(
beta=self.skip,
theta=self.layers[0],
lambda_=lambda_,
lambda_bar=lambda_bar,
M=M,
)
else:
with torch.no_grad():
inplace_group_prox(
groups=self.groups,
beta=self.skip,
theta=self.layers[0],
lambda_=lambda_,
lambda_bar=lambda_bar,
M=M,
)
def lambda_start(
self,
M=1,
lambda_bar=0,
factor=2,
):
"""Estimate when the model will start to sparsify."""
def is_sparse(lambda_):
with torch.no_grad():
beta = self.skip.weight.data
theta = self.layers[0].weight.data
for _ in range(10000):
new_beta, theta = prox(
beta,
theta,
lambda_=lambda_,
lambda_bar=lambda_bar,
M=M,
)
if torch.abs(beta - new_beta).max() < 1e-5:
break
beta = new_beta
return (torch.norm(beta, p=2, dim=0) == 0).sum()
start = 1e-6
while not is_sparse(factor * start):
start *= factor
return start
def l2_regularization(self):
"""
L2 regulatization of the MLP without the first layer
which is bounded by the skip connection
"""
ans = 0
for layer in islice(self.layers, 1, None):
ans += (
torch.norm(
layer.weight.data,
p=2,
)
** 2
)
return ans
def l1_regularization_skip(self):
return torch.norm(self.skip.weight.data, p=2, dim=0).sum()
def l2_regularization_skip(self):
return torch.norm(self.skip.weight.data, p=2)
def input_mask(self):
with torch.no_grad():
return torch.norm(self.skip.weight.data, p=2, dim=0) != 0
def selected_count(self):
return self.input_mask().sum().item()
def cpu_state_dict(self):
return {k: v.detach().clone().cpu() for k, v in self.state_dict().items()}
configs = toml.load("D:/rtdl-revisiting-models-main/output/adult/lassoNet/tunning/0.toml")
def objective(trial):
config = deepcopy(configs['base_config'])
merge_sampled_parameters(
config, sample_parameters(trial, configs['optimization']['space'], config)
)
model = LassoNet(
d_numerical=0 if D_train.X_num is None else D_train.X_num.shape[1],
categories = None if D_train.X_cat is None else [len(set(D_train.X_cat[:, i].tolist())) for i in range(D_train.X_cat.shape[1])],
d_out=D_train.info['n_classes'] if D_train.info["task_type"]=="multiclass" else 1
,**config['model']
).to(device)
parameters_with_wd = [v for k, v in model.named_parameters() if needs_wd(k)]
parameters_without_wd = [v for k, v in model.named_parameters() if not needs_wd(k)]
loss_fn = (
F.binary_cross_entropy_with_logits
if D_train.info["task_type"]=="binclass"
else F.cross_entropy
if D_train.info["task_type"]=="multiclass"
else F.mse_loss
)
optimizer = make_optimizer(
config["training"]["optimizer"],
(
[
{'params': parameters_with_wd},
{'params': parameters_without_wd, 'weight_decay': 0.0},
]
),
config["training"]["lr"],#to be trained in optuna
config["training"]["weight_decay"]#to be trained in optuna
)
loss_best = np.nan
best_epoch = -1
patience = 0
def save_state():
torch.save(
model.state_dict(),os.path.join(os.getcwd(),"lassonet_state.pickle")
)
with open(os.path.join(os.getcwd(),"best_state_lassonet.json"),"w") as f:
json.dump(config,f)
#dl_train.batch_size=config['training']['batch_size']
for epoch in range(config['training']['n_epochs']):
model.train()
for i,(x_num,x_cat,y) in enumerate(dl_train):
optimizer.zero_grad()
# y_batch = model(x_num,x_cat)
loss = 0
def closure():
nonlocal loss
optimizer.zero_grad()
ans = (
loss_fn(model(x_num,x_cat), y)
+ model.gamma * model.l2_regularization()
+ model.gamma_skip * model.l2_regularization_skip()
)
ans.backward() #相当于第7行Compute gradient of the loss
loss += ans.item()# * len(batch) / n_train
return ans
optimizer.step(closure)
model.prox(lambda_=model.lambda_ * optimizer.param_groups[0]["lr"], M=model.M) #Hier-Prox算法
model.eval()
with torch.no_grad():
for i,(x_num,x_cat,y) in enumerate(dl_val): #只有1个迭代
y_batch = model(x_num,x_cat)#.reshape((y_batch.shape[0],1))
loss = (
loss_fn(y_batch.reshape((y_batch.shape[0],1)), y).item()
+ model.gamma * model.l2_regularization().item()
+ model.gamma_skip * model.l2_regularization_skip().item()
+ model.lambda_ * model.l1_regularization_skip().item()
)
new_loss = loss#.detach()
if np.isnan(loss_best) or new_loss < loss_best:
patience = 0
best_epoch = epoch
loss_best = new_loss#.cpu().numpy()
save_state()
else:
patience+=1
if patience>= config['training']['patience']:
break
return loss_best
study = optuna.create_study(
direction="minimize",
sampler=optuna.samplers.TPESampler(**configs['optimization']['sampler']),
)
study.optimize(
objective,
**configs['optimization']['options'],
#callbacks=[save_checkpoint],
show_progress_bar=True,
)
对15个随机数种子进行建模并记录结果
## 模型定义部分同上,不再赘述
ArrayDict = ty.Dict[str, np.ndarray]
def normalize(
X, normalization,seed,noise=1e-3
):
X_train = X['train'].copy()
if normalization == 'standard':
normalizer = sklearn.preprocessing.StandardScaler()
elif normalization == 'quantile':
normalizer = sklearn.preprocessing.QuantileTransformer(
output_distribution='normal',
n_quantiles=max(min(X['train'].shape[0] // 30, 1000), 10),
subsample=int(1e9),
random_state=seed,
)
if noise:
stds = np.std(X_train, axis=0, keepdims=True)
noise_std = noise / np.maximum(stds, noise) # type: ignore[code]
X_train += noise_std * np.random.default_rng(seed).standard_normal( # type: ignore[code]
X_train.shape
)
else:
raise ValueError('Unknow normalization')
normalizer.fit(X_train)
return {k: normalizer.transform(v) for k, v in X.items()} # type: ignore[code]
class CustomDataset(Dataset):
def __init__(self,dir_,data_part,normalization,num_nan_policy,cat_nan_policy,
cat_policy,seed,
y_poicy=None,cat_min_frequency=0
):
super(CustomDataset,self).__init__()
dir_ = Path(dir_)
def load(item) -> ArrayDict:
return {
x: ty.cast(np.ndarray, np.load(dir_ / f'{item}_{x}.npy')) # type: ignore[code]
for x in ['train', 'val', 'test']
}
self.N = load('N') if dir_.joinpath('N_train.npy').exists() else None
self.C = load('C') if dir_.joinpath('C_train.npy').exists() else None
self.y = load('y')
self.info = json.loads((dir_ / 'info.json').read_text())
#pre-process
cache_path = f"build_dataset_{normalization}__{num_nan_policy}__{cat_nan_policy}__{cat_policy}__{seed}.pickle"
if cat_min_frequency>0:
cache_path = cache_path.replace('.pickle', f'__{cat_min_frequency}.pickle')
cache_path = Path(cache_path)
if cache_path.exists():
print("Using cache")
with open(cache_path, 'rb') as f:
data = pickle.load(f)
self.x = data
else:
def save_result(x):
if cache_path:
with open(cache_path, 'wb') as f:
pickle.dump(x, f)
if self.N:
N = deepcopy(self.N)
num_nan_masks = {k: np.isnan(v) for k, v in N.items()}
if any(x.any() for x in num_nan_masks.values()): # type: ignore[code]
if num_nan_policy == 'mean':
num_new_values = np.nanmean(self.N['train'], axis=0)
else:
raise ValueError('Unknown numerical NaN policy')
for k, v in N.items():
num_nan_indices = np.where(num_nan_masks[k])
v[num_nan_indices] = np.take(num_new_values, num_nan_indices[1])
if normalization:
N = normalize(N, normalization, seed)
else:
N = None
C = deepcopy(self.C)
cat_nan_masks = {k: v == 'nan' for k, v in C.items()}
if any(x.any() for x in cat_nan_masks.values()): # type: ignore[code]
if cat_nan_policy == 'new':
cat_new_value = '___null___'
imputer = None
elif cat_nan_policy == 'most_frequent':
cat_new_value = None
imputer = SimpleImputer(strategy=cat_nan_policy) # type: ignore[code]
imputer.fit(C['train'])
else:
raise ValueError('Unknown categorical NaN policy')
if imputer:
C = {k: imputer.transform(v) for k, v in C.items()}
else:
for k, v in C.items():
cat_nan_indices = np.where(cat_nan_masks[k])
v[cat_nan_indices] = cat_new_value
if cat_min_frequency:
C = ty.cast(ArrayDict, C)
min_count = round(len(C['train']) * cat_min_frequency)
rare_value = '___rare___'
C_new = {x: [] for x in C}
for column_idx in range(C['train'].shape[1]):
counter = Counter(C['train'][:, column_idx].tolist())
popular_categories = {k for k, v in counter.items() if v >= min_count}
for part in C_new:
C_new[part].append(
[
(x if x in popular_categories else rare_value)
for x in C[part][:, column_idx].tolist()
]
)
C = {k: np.array(v).T for k, v in C_new.items()}
unknown_value = np.iinfo('int64').max - 3
encoder = sklearn.preprocessing.OrdinalEncoder(
handle_unknown='use_encoded_value', # type: ignore[code]
unknown_value=unknown_value, # type: ignore[code]
dtype='int64', # type: ignore[code]
).fit(C['train'])
C = {k: encoder.transform(v) for k, v in C.items()}
max_values = C['train'].max(axis=0)
for part in ['val', 'test']:
for column_idx in range(C[part].shape[1]):
C[part][C[part][:, column_idx] == unknown_value, column_idx] = (
max_values[column_idx] + 1
)
if cat_policy == 'indices':
result = (N, C)
elif cat_policy == 'ohe':
ohe = sklearn.preprocessing.OneHotEncoder(
handle_unknown='ignore', sparse=False, dtype='float32' # type: ignore[code]
)
ohe.fit(C['train'])
C = {k: ohe.transform(v) for k, v in C.items()}
result = (N, C)
#result = C if N is None else {x: np.hstack((N[x], C[x])) for x in N}
elif cat_policy == 'counter':
assert seed is not None
loo = LeaveOneOutEncoder(sigma=0.1, random_state=seed, return_df=False)
loo.fit(C['train'], self.y['train'])
C = {k: loo.transform(v).astype('float32') for k, v in C.items()} # type: ignore[code]
if not isinstance(C['train'], np.ndarray):
C = {k: v.values for k, v in C.items()} # type: ignore[code]
if normalization:
C = normalize(C, normalization, seed, inplace=True) # type: ignore[code]
result = (N, C)
#result = C if N is None else {x: np.hstack((N[x], C[x])) for x in N}
else:
raise ValueError('Unknow categorical policy')
save_result(result)
self.x = result
self.X_num,self.X_cat = self.x
self.X_num = None if self.X_num is None else self.X_num[data_part]
self.X_cat = None if self.X_cat is None else self.X_cat[data_part]
# build Y
if self.info['task_type'] == 'regression':
assert policy == 'mean_std'
y = deepcopy(self.y)
if y_poicy:
if not self.info['task_type'] == 'regression':
warnings.warn('y_policy is not None, but the task is NOT regression')
info = None
elif y_poicy == 'mean_std':
mean, std = self.y['train'].mean(), self.y['train'].std()
y = {k: (v - mean) / std for k, v in y.items()}
info = {'policy': policy, 'mean': mean, 'std': std}
else:
raise ValueError('Unknow y policy')
else:
info = None
self.y = y[data_part]
if len(self.y.shape)==1:
self.y = self.y.reshape((self.y.shape[0],1))
self.y_info = info
def __len__(self):
X = self.X_num if self.X_num is not None else self.X_cat
return len(X)
def __getitem__(self,idx):
return torch.FloatTensor(self.X_num[idx]).to(device),torch.IntTensor(self.X_cat[idx]).to(device),torch.FloatTensor(self.y[idx]).to(device)
##读设定文件
import pytomlpp as toml
xgboost_config = toml.load("xgboost.toml")
lightGBM_config = toml.load("lightgbm.toml")
ft_transformer_config = toml.load("FT_TRANSFORMER.toml")
ft_transformer_mine_config = toml.load("FT_TRANSFORMER_MINE.toml")
resNet_config = toml.load("resnet.toml")
LassoNet_config = toml.load("LassoNet.toml")
def needs_wd(name):
return all(x not in name for x in ['tokenizer', '.norm', '.bias'])
def make_optimizer(
optimizer: str,
parameter_groups,
lr: float,
weight_decay: float,
) -> optim.Optimizer:
Optimizer = {
'adam': optim.Adam,
'adamw': optim.AdamW,
'sgd': optim.SGD,
}[optimizer]
momentum = (0.9,) if Optimizer is optim.SGD else ()
return Optimizer(parameter_groups, lr, *momentum, weight_decay=weight_decay)
def train_model_xgboost(model,fit_kwargs,dataset_train,dataset_valid,dataset_test,seed):
model_state_dict_path = os.path.join(os.getcwd(),f"xgboost_state_seed_{seed}.pickle")
model_result_records = "xgboost_Result.txt"
feature_importance_record_path = f"xgboost_feature_importance_{seed}.npy"
if os.path.exists(model_state_dict_path):
return
X_train = dataset_train.X_cat if dataset_train.X_num is None else np.hstack((dataset_train.X_num, dataset_train.X_cat))
Y_train = dataset_train.y
X_valid = dataset_valid.X_cat if dataset_valid.X_num is None else np.hstack((dataset_valid.X_num, dataset_valid.X_cat))
Y_valid = dataset_valid.y
X_test = dataset_test.X_cat if dataset_test.X_num is None else np.hstack((dataset_test.X_num, dataset_test.X_cat))
Y_test = dataset_test.y
fit_kwargs['eval_set'] = [(X_valid,Y_valid)]
model.fit(X_train, Y_train, **fit_kwargs)
prediction = model.predict(X_test)
result = skm.classification_report(Y_test, prediction, output_dict=True)
model.save_model(model_state_dict_path)
recall = result["1"]["recall"]
acc = result['accuracy']
with open(model_result_records,"a") as f:
f.write(f"seed{seed} accuracy is:{acc} and the recall is :{recall}\n")
np.save(feature_importance_record_path, model.feature_importances_)
def train_model_lightGBM(model,fit_kwargs,dataset_train,dataset_valid,dataset_test,seed):
model_state_dict_path = os.path.join(os.getcwd(),f"lightGBM_state_seed_{seed}.pickle")
model_result_records = "lightGBM_Result.txt"
feature_importance_record_path = f"lightGBM_feature_importance_{seed}.npy"
if os.path.exists(model_state_dict_path):
return
X_train = dataset_train.X_cat if dataset_train.X_num is None else np.hstack((dataset_train.X_num, dataset_train.X_cat))
Y_train = dataset_train.y
X_valid = dataset_valid.X_cat if dataset_valid.X_num is None else np.hstack((dataset_valid.X_num, dataset_valid.X_cat))
Y_valid = dataset_valid.y
X_test = dataset_test.X_cat if dataset_test.X_num is None else np.hstack((dataset_test.X_num, dataset_test.X_cat))
Y_test = dataset_test.y
n_num_features = dataset_train.X_num.shape[1]
n_features = dataset_train.X_num.shape[1]+dataset_train.X_cat.shape[1]
fit_kwargs['categorical_feature'] = list(range(n_num_features, n_features))
model.fit(X_train, Y_train, **fit_kwargs,eval_set=(X_valid, Y_valid))
prediction = model.predict(X_test)
result = skm.classification_report(Y_test, prediction, output_dict=True)
recall = result["1"]["recall"]
acc = result['accuracy']
# joblib.dump(model, model_state_dict_path)
with open(model_result_records,"a") as f:
f.write(f"seed{seed} accuracy is:{acc} and the recall is :{recall}\n")
np.save(feature_importance_record_path, model.feature_importances_)
def train_model(model,config,dl_train,dl_valid,dl_test,seed,model_type,is_mine=False):
model_state_dict_path = os.path.join(os.getcwd(),f"{model_type}_state_seed_{seed}.pickle")
model_result_records = f"{model_type}_Result.txt"
if is_mine:
model_state_dict_path = model_state_dict_path.replace(".pickle","_mine.pickle")
model_result_records = model_result_records.replace(".txt","_mine.txt")
if os.path.exists(model_state_dict_path):
return
parameters_with_wd = [v for k, v in model.named_parameters() if needs_wd(k)]
parameters_without_wd = [v for k, v in model.named_parameters() if not needs_wd(k)]
loss_fn = F.binary_cross_entropy_with_logits
optimizer = make_optimizer(
config["training"]["optimizer"],
(
[
{'params': parameters_with_wd},
{'params': parameters_without_wd, 'weight_decay': 0.0},
]
),
config["training"]["lr"],#to be trained in optuna
config["training"]["weight_decay"]#to be trained in optuna
)
loss_best = np.nan
best_epoch = -1
patience = 0
def save_state():
torch.save(
model.state_dict(),model_state_dict_path
)
#dl_train.batch_size=config['training']['batch_size']
for epoch in range(config['training']['n_epochs']):
model.train()
for i,(x_num,x_cat,y) in enumerate(dl_train):
optimizer.zero_grad()
y_batch = model(x_num,x_cat)
loss = loss_fn(y_batch.reshape((y_batch.shape[0],1)),y)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
for i,(x_num,x_cat,y) in enumerate(dl_valid): #只有1个迭代
y_batch = model(x_num,x_cat)
loss = loss_fn(y_batch.reshape((y_batch.shape[0],1)),y)
new_loss = loss.detach()
if np.isnan(loss_best) or new_loss.cpu().numpy() < loss_best:
patience = 0
best_epoch = epoch
loss_best = new_loss.cpu().numpy()
save_state()
else:
patience+=1
if patience>= config['training']['patience']:
break
#读取state_dict
model.load_state_dict(
torch.load(model_state_dict_path)
)
model.eval()
with torch.no_grad():
for i,(x_num,x_cat,y) in enumerate(dl_test): #只有1个迭代
y_batch = model(x_num,x_cat)
prediction = y_batch.cpu().numpy()
prediction = np.round(scipy.special.expit(prediction)).astype('int64')
result = skm.classification_report(y.cpu().numpy(), prediction, output_dict=True)
recall = result["1.0"]["recall"]
acc = result['accuracy']
with open(model_result_records,"a") as f:
f.write(f"seed{seed} accuracy is:{acc} and the recall is :{recall}\n")
def train_model_LassoNet(model,config,dl_train,dl_valid,dl_test,seed):
model_state_dict_path = os.path.join(os.getcwd(),f"lassoNet_state_seed_{seed}.pickle")
model_result_records = f"lassoNet_Result.txt"
if os.path.exists(model_state_dict_path):
return
parameters_with_wd = [v for k, v in model.named_parameters() if needs_wd(k)]
parameters_without_wd = [v for k, v in model.named_parameters() if not needs_wd(k)]
loss_fn = F.binary_cross_entropy_with_logits
optimizer = make_optimizer(
config["training"]["optimizer"],
(
[
{'params': parameters_with_wd},
{'params': parameters_without_wd, 'weight_decay': 0.0},
]
),
config["training"]["lr"],#to be trained in optuna
config["training"]["weight_decay"]#to be trained in optuna
)
loss_best = np.nan
best_epoch = -1
patience = 0
def save_state():
torch.save(
model.state_dict(),model_state_dict_path
)
#dl_train.batch_size=config['training']['batch_size']
for epoch in range(config['training']['n_epochs']):
model.train()
for i,(x_num,x_cat,y) in enumerate(dl_train):
optimizer.zero_grad()
# y_batch = model(x_num,x_cat)
loss = 0
def closure():
nonlocal loss
optimizer.zero_grad()
ans = (
loss_fn(model(x_num,x_cat), y)
+ model.gamma * model.l2_regularization()
+ model.gamma_skip * model.l2_regularization_skip()
)
ans.backward() #相当于第7行Compute gradient of the loss
loss += ans.item()# * len(batch) / n_train
return ans
optimizer.step(closure)
model.prox(lambda_=model.lambda_ * optimizer.param_groups[0]["lr"], M=model.M) #Hier-Prox算法
model.eval()
with torch.no_grad():
for i,(x_num,x_cat,y) in enumerate(dl_valid): #只有1个迭代
y_batch = model(x_num,x_cat)#.reshape((y_batch.shape[0],1))
loss = (
loss_fn(y_batch.reshape((y_batch.shape[0],1)), y).item()
+ model.gamma * model.l2_regularization().item()
+ model.gamma_skip * model.l2_regularization_skip().item()
+ model.lambda_ * model.l1_regularization_skip().item()
)
new_loss = loss#.detach()
if np.isnan(loss_best) or new_loss < loss_best:
patience = 0
best_epoch = epoch
loss_best = new_loss#.cpu().numpy()
save_state()
else:
patience+=1
if patience>= config['training']['patience']:
break
#读取state_dict
model.load_state_dict(
torch.load(model_state_dict_path)
)
model.eval()
with torch.no_grad():
for i,(x_num,x_cat,y) in enumerate(dl_test): #只有1个迭代
y_batch = model(x_num,x_cat)
prediction = y_batch.cpu().numpy()
prediction = np.round(scipy.special.expit(prediction)).astype('int64')
result = skm.classification_report(y.cpu().numpy(), prediction, output_dict=True)
recall = result["1.0"]["recall"]
acc = result['accuracy']
with open(model_result_records,"a") as f:
f.write(f"seed{seed} accuracy is:{acc} and the recall is :{recall}\n")
import sklearn.metrics as skm
## 设定训练参数
def train_by_model(configs,seed,model_type):
zero.set_randomness(seed)
def build_dataloaders(configs):
data_configs = configs["data"]
D_train = CustomDataset(
data_path_father+"adult"
,data_part="train"
,normalization=data_configs.get("normalization")
,num_nan_policy="mean"
,cat_nan_policy="new"
,cat_policy=data_configs.get("cat_policy", 'indices')
,seed=seed
,y_poicy=data_configs.get("y_policy"),cat_min_frequency=0
)
D_valid = CustomDataset(
data_path_father+"adult"
,data_part="val"
,normalization=data_configs.get("normalization")
,num_nan_policy="mean"
,cat_nan_policy="new"
,cat_policy=data_configs.get("cat_policy", 'indices')
,seed=seed
,y_poicy=data_configs.get("y_policy"),cat_min_frequency=0
)
D_test = CustomDataset(
data_path_father+"adult"
,data_part="test"
,normalization=data_configs.get("normalization")
,num_nan_policy="mean"
,cat_nan_policy="new"
,cat_policy=data_configs.get("cat_policy", 'indices')
,seed=seed
,y_poicy=data_configs.get("y_policy"),cat_min_frequency=0
)
dl_train = DataLoader(D_train,batch_size=256)
dl_val = DataLoader(D_valid,batch_size=len(D_valid))
dl_test = DataLoader(D_test,batch_size=len(D_test))
return D_train,D_valid,D_test,dl_train,dl_val,dl_test
D_train,D_valid,D_test,dl_train,dl_valid,dl_test = build_dataloaders(configs)
if "FT_Transformer" in model_type:
configs["model"].setdefault('token_bias', True)
configs["model"].setdefault('kv_compression', None)
configs["model"].setdefault('kv_compression_sharing', None)
model = Transformer(d_numerical=0 if D_train.X_num is None else D_train.X_num.shape[1],
categories = None if D_train.X_cat is None else [len(set(D_train.X_cat[:, i].tolist())) for i in range(D_train.X_cat.shape[1])],
d_out=D_train.info['n_classes'] if D_train.info["task_type"]=="multiclass" else 1
,**configs['model']).to(device)
is_mine = model_type.endswith("_mine")
train_model(model,configs,dl_train,dl_valid,dl_test,seed,"FT_Transformer",is_mine=is_mine)
elif model_type == "LassoNet":
model = LassoNet(
d_numerical=0 if D_train.X_num is None else D_train.X_num.shape[1],
categories = None if D_train.X_cat is None else [len(set(D_train.X_cat[:, i].tolist())) for i in range(D_train.X_cat.shape[1])],
d_out=D_train.info['n_classes'] if D_train.info["task_type"]=="multiclass" else 1
,**configs['model']
).to(device)
train_model_LassoNet(model,configs,dl_train,dl_valid,dl_test,seed)
elif model_type == "ResNet":
model = ResNet(
d_numerical=0 if D_train.X_num is None else D_train.X_num.shape[1],
categories = None if D_train.X_cat is None else [len(set(D_train.X_cat[:, i].tolist())) for i in range(D_train.X_cat.shape[1])],
d_out=D_train.info['n_classes'] if D_train.info["task_type"]=="multiclass" else 1,
**configs['model'],
).to(device)
train_model(model,configs,dl_train,dl_valid,dl_test,seed,"ResNet",is_mine=False)
elif model_type == "xgboost":
fit_kwargs = deepcopy(configs["fit"])
configs["model"]['random_state'] = seed
fit_kwargs['eval_metric'] = 'error'
model = XGBClassifier(**configs["model"])
train_model_xgboost(model,fit_kwargs,D_train,D_valid,D_test,seed)
elif model_type == "lightGBM":
model_kwargs = deepcopy(configs['model'])
model_kwargs['random_state'] = seed
fit_kwargs = deepcopy(configs['fit'])
early_stop_rounds = fit_kwargs.get("early_stopping_rounds")
del fit_kwargs["early_stopping_rounds"]
del fit_kwargs["verbose"]
fit_kwargs['eval_metric'] = 'binary_error'
ES = early_stopping(early_stop_rounds)
verbose = log_evaluation(10**8)
model = LGBMClassifier(**model_kwargs,callbacks = [ES,verbose])
train_model_lightGBM(model,fit_kwargs,D_train,D_valid,D_test,seed)
else:
raise ValueError("model_type not recognized")
seeds=[6368,1658,8366,8641,7052,7600,297,5829,9295,1698,2157,3318,8312,7741,9570]
for i,seed in enumerate(seeds):
train_by_model(xgboost_config,seed,"xgboost")
train_by_model(lightGBM_config,seed,"lightGBM")
train_by_model(ft_transformer_config,seed,"FT_Transformer")
train_by_model(ft_transformer_mine_config,seed,"FT_Transformer_mine")
train_by_model(resNet_config,seed,"ResNet")
train_by_model(LassoNet_config,seed,"LassoNet")智能推荐
FTP命令字和返回码_ftp 登录返回230-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏13次。为了从FTP服务器下载文件,需要要实现一个简单的FTP客户端。FTP(文件传输协议) 是 TCP/IP 协议组中的应用层协议。FTP协议使用字符串格式命令字,每条命令都是一行字符串,以“\r\n”结尾。客户端发送格式是:命令+空格+参数+"\r\n"的格式服务器返回格式是以:状态码+空格+提示字符串+"\r\n"的格式,代码只要解析状态码就可以了。读写文件需要登陆服务器,特殊用..._ftp 登录返回230
centos7安装rabbitmq3.6.5_centos7 安装rabbitmq3.6.5-程序员宅基地
文章浏览阅读648次。前提:systemctl stop firewalld 关闭防火墙关闭selinux查看getenforce临时关闭setenforce 0永久关闭sed-i'/SELINUX/s/enforcing/disabled/'/etc/selinux/configselinux的三种模式enforcing:强制模式,SELinux 运作中,且已经正确的开始限制..._centos7 安装rabbitmq3.6.5
idea导入android工程,idea怎样导入Android studio 项目?-程序员宅基地
文章浏览阅读5.8k次。满意答案s55f2avsx2017.09.05采纳率:46%等级:12已帮助:5646人新版Android Studio/IntelliJ IDEA可以直接导入eclipse项目,不再推荐使用eclipse导出gradle的方式2启动Android Studio/IntelliJ IDEA,选择 import project3选择eclipse 项目4选择 create project f..._android studio 项目导入idea 看不懂安卓项目
浅谈AI大模型技术:概念、发展和应用_ai大模型应用开发-程序员宅基地
文章浏览阅读860次,点赞2次,收藏6次。AI大模型技术已经在自然语言处理、计算机视觉、多模态交互等领域取得了显著的进展和成果,同时也引发了一系列新的挑战和问题,如数据质量、计算效率、知识可解释性、安全可靠性等。城市运维涉及到多个方面,如交通管理、环境监测、公共安全、社会治理等,它们需要处理和分析大量的多模态数据,如图像、视频、语音、文本等,并根据不同的场景和需求,提供合适的决策和响应。知识搜索有多种形式,如语义搜索、对话搜索、图像搜索、视频搜索等,它们可以根据用户的输入和意图,从海量的数据源中检索出最相关的信息,并以友好的方式呈现给用户。_ai大模型应用开发
非常详细的阻抗测试基础知识_阻抗实部和虚部-程序员宅基地
文章浏览阅读8.2k次,点赞12次,收藏121次。为什么要测量阻抗呢?阻抗能代表什么?阻抗测量的注意事项... ...很多人可能会带着一系列的问题来阅读本文。不管是数字电路工程师还是射频工程师,都在关注各类器件的阻抗,本文非常值得一读。全文13000多字,认真读完大概需要2小时。一、阻抗测试基本概念阻抗定义:阻抗是元器件或电路对周期的交流信号的总的反作用。AC 交流测试信号 (幅度和频率)。包括实部和虚部。图1 阻抗的定义阻抗是评测电路、元件以及制作元件材料的重要参数。那么什么是阻抗呢?让我们先来看一下阻抗的定义。首先阻抗是一个矢量。通常,阻抗是_阻抗实部和虚部
小学生python游戏编程arcade----基本知识1_arcade语言 like-程序员宅基地
文章浏览阅读955次。前面章节分享试用了pyzero,pygame但随着想增加更丰富的游戏内容,好多还要进行自己编写类,从今天开始解绍一个新的python游戏库arcade模块。通过此次的《连连看》游戏实现,让我对swing的相关知识有了进一步的了解,对java这门语言也有了比以前更深刻的认识。java的一些基本语法,比如数据类型、运算符、程序流程控制和数组等,理解更加透彻。java最核心的核心就是面向对象思想,对于这一个概念,终于悟到了一些。_arcade语言 like
随便推点
【增强版短视频去水印源码】去水印微信小程序+去水印软件源码_去水印机要增强版-程序员宅基地
文章浏览阅读1.1k次。源码简介与安装说明:2021增强版短视频去水印源码 去水印微信小程序源码网站 去水印软件源码安装环境(需要材料):备案域名–服务器安装宝塔-安装 Nginx 或者 Apachephp5.6 以上-安装 sg11 插件小程序已自带解析接口,支持全网主流短视频平台,搭建好了就能用注:接口是公益的,那么多人用解析慢是肯定的,前段和后端源码已经打包,上传服务器之后在配置文件修改数据库密码。然后输入自己的域名,进入后台,创建小程序,输入自己的小程序配置即可安装说明:上传源码,修改data/_去水印机要增强版
verilog进阶语法-触发器原语_fdre #(.init(1'b0) // initial value of register (1-程序员宅基地
文章浏览阅读557次。1. 触发器是FPGA存储数据的基本单元2. 触发器作为时序逻辑的基本元件,官方提供了丰富的配置方式,以适应各种可能的应用场景。_fdre #(.init(1'b0) // initial value of register (1'b0 or 1'b1) ) fdce_osc (
嵌入式面试/笔试C相关总结_嵌入式面试笔试c语言知识点-程序员宅基地
文章浏览阅读560次。本该是不同编译器结果不同,但是尝试了g++ msvc都是先计算c,再计算b,最后得到a+b+c是经过赋值以后的b和c参与计算而不是6。由上表可知,将q复制到p数组可以表示为:*p++=*q++,*优先级高,先取到对应q数组的值,然后两个++都是在后面,该行运算完后执行++。在电脑端编译完后会分为text data bss三种,其中text为可执行程序,data为初始化过的ro+rw变量,bss为未初始化或初始化为0变量。_嵌入式面试笔试c语言知识点
57 Things I've Learned Founding 3 Tech Companies_mature-程序员宅基地
文章浏览阅读2.3k次。57 Things I've Learned Founding 3 Tech CompaniesJason Goldberg, Betashop | Oct. 29, 2010, 1:29 PMI’ve been founding andhelping run techn_mature
一个脚本搞定文件合并去重,大数据处理,可以合并几个G以上的文件_python 超大文本合并-程序员宅基地
文章浏览阅读1.9k次。问题:先讲下需求,有若干个文本文件(txt或者csv文件等),每行代表一条数据,现在希望能合并成 1 个文本文件,且需要去除重复行。分析:一向奉行简单原则,如无必要,绝不复杂。如果数据量不大,那么如下两条命令就可以搞定合并:cat a.txt >> new.txtcat b.txt >> new.txt……去重:cat new...._python 超大文本合并
支付宝小程序iOS端过渡页DFLoadingPageRootController分析_类似支付宝页面过度加载页-程序员宅基地
文章浏览阅读489次。这个过渡页是第一次打开小程序展示的,点击某个小程序前把手机的开发者->network link conditioner->enable & very bad network 就会在停在此页。比如《支付宝运动》这个小程序先看这个类的.h可以看到它继承于DTViewController点击左上角返回的方法- (void)back;#import "DTViewController.h"#import "APBaseLoadingV..._类似支付宝页面过度加载页