
我们平时所说的埋点,可以大致分为两部分,一部分是统计APP页面访问情况,即页面统计;另外一部分是统计APP内的操作行为,及自定义事件统计。
一、页面统计
页面统计,可以统计应用内各个页面的访问次数(PV),访问设备数(UV)和访问时长,以及各页面之间的流向关系。
1.1 页面访问数
页面访问次数,即当前页面的被访问的次数,即浏览量PV;举例:首页,访问次数,1000次;
页面访问人数,即访问该页面的活跃用户数,即独立访问数UV;举例:首页,访问人数,100次;
1.2 页面访问时长
页面访问时长,用户在页面的停留时长,即首页受访时长的总和;举例:首页,访问总时长,2小时;
1.3页面流向分布
页面流向(走向)分布,可统计出,当前页面和下一个页面(有多个)的流向关系;
举例1:在“商品详情”这个页面中,可以进入“购买”、“收藏”、“返回列表”、共3个页面,即在“商品详情”页,可能的流向分布为:
其中,用户在该“商品详情”页面,没有进入对应的3个页面,即视为“离开应用”,在页面流向分布,有2个常见问题:
二、自定义事件统计
自定义事件,即记录用户的操作行为(如点击行为),记录用户操作行为中的具体细节;一般来说,通常所说的埋点,指的就是自定义事件。
埋点可以是某个按钮,某个点击区域,某个提示,甚至可以用来统计一些特定的代码是否被执行。在APP中,需要在代码中定义一个事件行为。
2.1简单事件统计
简单事件统计,即记录事件的发生次数(可理解为PV)和事件发生人数(可理解为UV)。
以下面的登录页为例:
其事件统计的结果为:
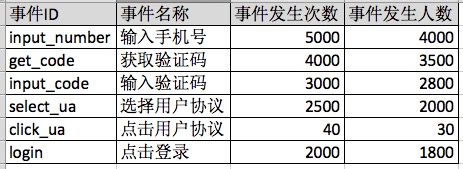
事件ID,即EventID,该名称可由程序员自行定义(按照APP统计平台,如友盟、talkingdata等提供的事件ID命名规范进行命名),将该事件ID写入需要跟踪的位置中即可。
事件名称,可以理解为事件ID的一个中文翻译名称,是为了方便运营人员查看,事件名称命名是在APP上线后,该事件ID有数据后的一个事后行为,通常是在APP数据平台中定义(如果你乐意,你可以把input_number这个事件ID的事件名称改为:用户在这里输入手机号)。事件名称只是事件ID在前端页面的一个显示名称。
事件发生次数,即该事件总共发生的次数;可以理解为,在每个事件中,都会有个事件ID计数器,每当该事件被触发时,事件数即加1;
事件发生人数,即该事件的发生人数(有些APP统计平台也称之为:达成该事件的用户数、独立用户数);参考事件发生次数,可以理解为,在每个事件中,都会有个事件ID计数器,每当该事件被触发时,同时记录下该用户的唯一标识,事件数即加1;事件发生人数,即根据用户唯一标识,对事件发生次数进行去重。
三、常用前端埋点方案总结
在上一节中介绍了前端监控的作用,那么如何实现前端监控呢,实现前端监控的步骤为:前端埋点和上报、数据处理和数据分析。首要的步骤就是前端埋点和上报,也就是数据的收集阶段。数据收集的丰富性和准确性会影响对产品线上效果的判别结果。
目前常见的前端埋点方法分为三种:代码埋点、可视化埋点和无痕埋点。下面一一介绍每一种埋点的方法。
(1) 代码埋点
代码埋点,就是以嵌入代码的形式进行埋点,比如需要监控用户的点击事件,会选择在用户点击时,插入一段代码,保存这个监听行为或者直接将监听行为以某一种数据格式直接传递给server端。此外比如需要统计产品的PV和UV的时候,需要在网页的初始化时,发送用户的访问信息等。
代码埋点的优点:
-
可以在任意时刻,精确的发送或保存所需要的数据信息。
缺点:
-
工作量较大,每一个组件的埋点都需要添加相应的代码
(2)可视化埋点
通过可视化交互的手段,代替代码埋点。将业务代码和埋点代码分离,提供一个可视化交互的页面,输入为业务代码,通过这个可视化系统,可以在业务代码中自定义的增加埋点事件等等,最后输出的代码耦合了业务代码和埋点代码。
可视化埋点听起来比较高大上,实际上跟代码埋点还是区别不大。也就是用一个系统来实现手动插入代码埋点的过程。
缺点:
-
可视化埋点可以埋点的控件有限,不能手动定制。
(3)无埋点
无埋点并不是说不需要埋点,而是全部埋点,前端的任意一个事件都被绑定一个标识,所有的事件都别记录下来。通过定期上传记录文件,配合文件解析,解析出来我们想要的数据,并生成可视化报告供专业人员分析因此实现“无埋点”统计。
从语言层面实现无埋点也很简单,比如从页面的js代码中,找出dom上被绑定的事件,然后进行全埋点。
无埋点的优点:
-
由于采集的是全量数据,所以产品迭代过程中是不需要关注埋点逻辑的,也不会出现漏埋、误埋等现象
缺点:
-
无埋点采集全量数据,给数据传输和服务器增加压力
-
无法灵活的定制各个事件所需要上传的数据
四、前端埋点方案选型和前端上报方案设计
第一章中介绍了前端所需要监听的信息,在第二章中介绍了前端埋点的常见方式,本文来根据需求,来定制我们的埋点和上报方案。
(1)监控数据
首先我们需要明确一个产品或者网页,普遍需要监控和上报的数据。监控的分为三个阶段:用户进入网页首页、用户在网页内部交互和交互中报错。每一个阶段需要监控和上报的数据如下图所示:
(2)埋点方案
在实际项目中考虑到上报数据的灵活定制,以及减少数据传输和服务器的压力,在所需埋点处不多的情况下,常用的方式是代码埋点。
以用户进入首页为例,我们在首页渲染完成后会发送事件类型和类型相关的数据给server端,告知首页的监控信息。
(3)上报周期和上报数据类型
如果埋点的事件不是很多,上报可以时时进行,比如监控用户的交互事件,可以在用户触发事件后,立刻上报用户所触发的事件类型。如果埋点的事件较多,或者说网页内部交互频繁,可以通过本地存储的方式先缓存上报信息,然后定期上报。
接着来确定需要埋点上报的数据,上报的信息包括用户个人信息以及用户行为,主要数据可以分为:
-
who: appid(系统或者应用的id),userAgent(用户的系统、网络等信息)
-
when: timestamp(上报的时间戳)
-
from where: currentUrl(用户当前url),fromUrl(从哪一个页面跳转到当前页面),type(上报的事件类型),element(触发上报事件的元素)
-
what: 上报的自定义扩展数据data:{},扩展数据中可以按需求定制,比如包含uid等信息
参考连接:http://www.woshipm.com/data-analysis/450268.html
http://www.cnblogs.com/liuhao-web/p/9609884.html
https://blog.csdn.net/zhuhengv/article/details/50911482