博客管理系统|基于SpringBoot+Vue+ElementUI付费博客系统的设计与实现-程序员宅基地
技术标签: spring boot java 网站平台类 博客系统 java实战项目专栏 付费博客系统 后端
作者主页:编程指南针
作者简介:Java领域优质创作者、程序员宅基地专家 、掘金特邀作者、多年架构师设计经验、腾讯课堂常驻讲师
主要内容:Java项目、毕业设计、简历模板、学习资料、面试题库、技术互助
收藏点赞不迷路 关注作者有好处
文末获取源码
项目编号:BS-PT-089
二,环境介绍
语言环境:Java: jdk1.8
数据库:Mysql: mysql5.7+Redis
应用服务器:Tomcat: tomcat8.5.31
开发工具:IDEA或eclipse
后台开发技术:springboot+mybatis
前台开发技术:vue+elementUI
二,项目简介
随着网络的迅速崛起,让互联网逐渐成为人们日常生活沟通交流的主要媒介,而具体的交流方式也随着科技的进步不断更新。过去,人们并没 有己的博客,因此只能通过比较分散,又缺乏条理的方式来展现自己的想法与心情,例如通过即时聊天软件或是在论坛上发表贴子等,但这些方法操作复杂,对个人信息的安全保护性能也不是很强。因此随着博客在网络上的普及,人们便可以通过博客表达自己的思想与感受,展示自己并让更多的人了解你,可以说博客是不受局限,言论由的网络个人日记。博客作为一个可以让人们提高写作水平的训练基地,表达文字的网络载体,它注重对自我感受和生活表达,经常写博客能够极快的磨练博主的写作技巧,并能使其思想意识更加深刻、敏锐。
博客,又叫网络日志,是一个通常由个人管理,不定期发布新的文章的网站。博客上的文章通常根据发布的时间,用倒序的方式由新到旧排列。许多博客专注在特定的课题上提供评论和新闻,其他的被作为个人日记。一个典型的博客结合了文字、图像、其他博客或者网站的链接、以及其他相关的主题为主的媒体。能够让读者以互动的方式留下意见,是许多博客的重要要素。大部分的博客内容以文字为主,博客是社会媒体网络的一部分。
各大网站上都有自己的博客系统,但是功能上都有所不同和局限性,我们为了实现一种属于我们自己的博客系统,尽量做到功能简洁,页面美观,更方便于流行的博客系统。
前台包含有5个模块,如图1所示。
用户登录:用户在使用博客系统之前需要登录注册,注册的方式提供了手机号注册和邮箱注册,注册完后登录时还需要验证码验证,验证成功才能进入博客主页。
博客页面展示:主页展示的是所有人的博客信息,用户可以在这里可以根据关键词搜索博客,还可以评论博客,有喜欢的博客还可以收藏起来,还可以根据类型的不同找博客,还有排行榜可以看到优质博客。
个人中心:个人中心展示的是个人信息,订单管理钱包管理还有自己的博客,个人信息里面可以查看浏览记录,可以修改手机号码,邮箱,密码等等,这里还添加了一个身份证的认证。订单管理里面是购买收费博客和广告的记录。钱包里面可以查看余额,可以充值和提现,提现是提现在银行卡里面。
发表博客:发表博客之前要先选择博客的分类,在分类下去新增博客,还可以添加图片到博客中,博客新增完毕可以选择是否收费,选择完毕在发表。
广告模块:这是一个盈利的功能,当用户看博客的时候会有广告在附近,用户可以通过花钱的方式消除广告。
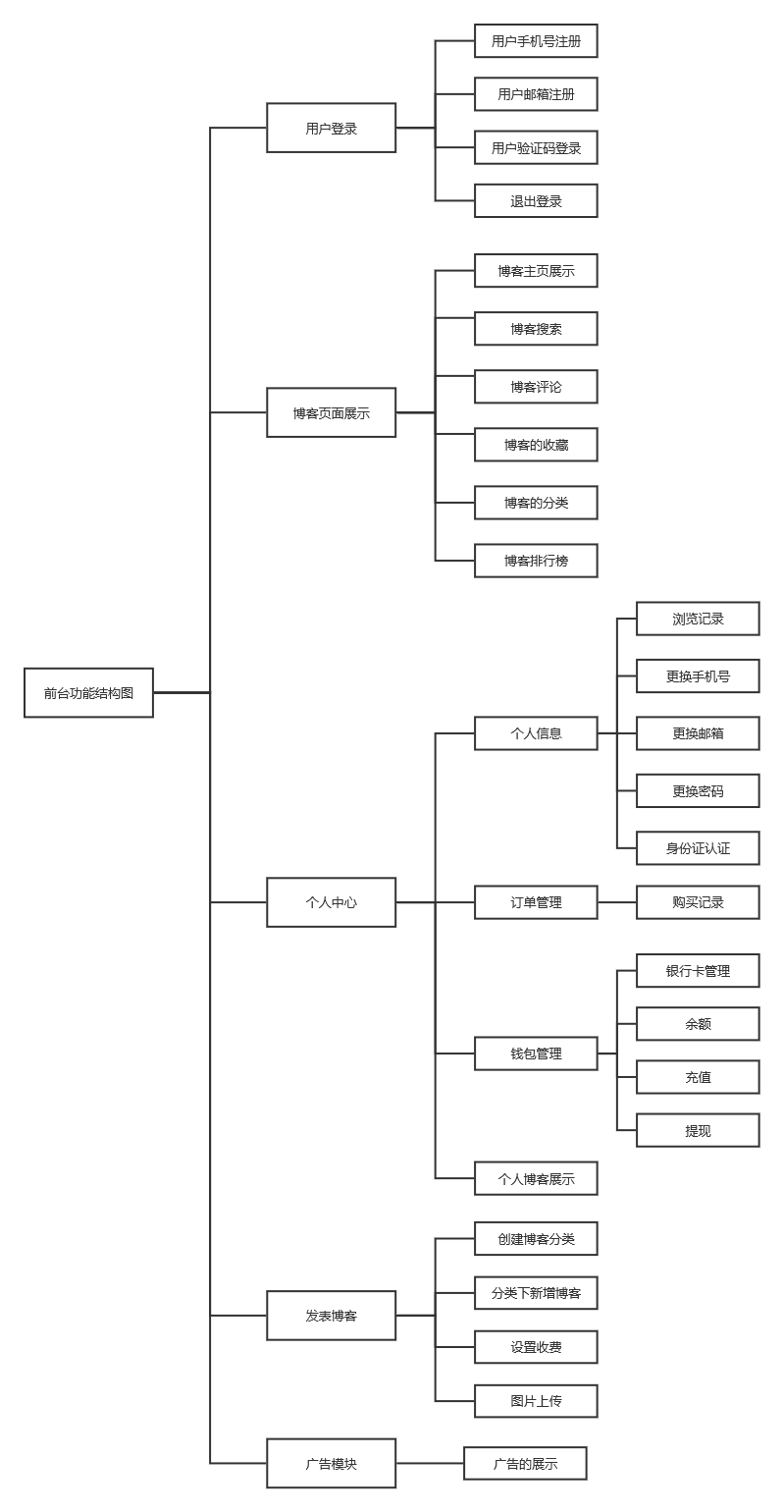
后台包含有6个模块,如图2所示。
用户管理:管理员可以新增用户,修改用户,删除用户,查询用户的信息,用户可以自己注册,也可以管理员手动进行注册,用户名不能重复,如果用户忘记了密码可以联系管理员进行密码重置。
博客审核:用户发布的博客,管理员需要审核,一些非法信息或者暴力的内容等不能展示出来,审核通过后管理员可以手动发布帖子,审核不通过会提示用户,审核不通过。
广告管理:管理员可以新增广告到博客主页上,还可以对广告进行删除,修改的操作,还可以查看广告。
博客管理:管理员可以删除用户发布的博客,也可以修改用户的博客,还可以查询博客。
订单管理:当用户花钱购买付费的博客或者广告时,会生成一个未支付订单,等用户付完款后会修改成已支付订单,主页才能查看博客或者消除广告。
充值提现审核:用户点击提现后,选择提现的金额,发起提现,此时会进入提现审核状态,后台会收到,当管理员审核状态修改成通过时,用户提现的金额才能存到银行卡中,管理员还可以随时查看审核的状态。
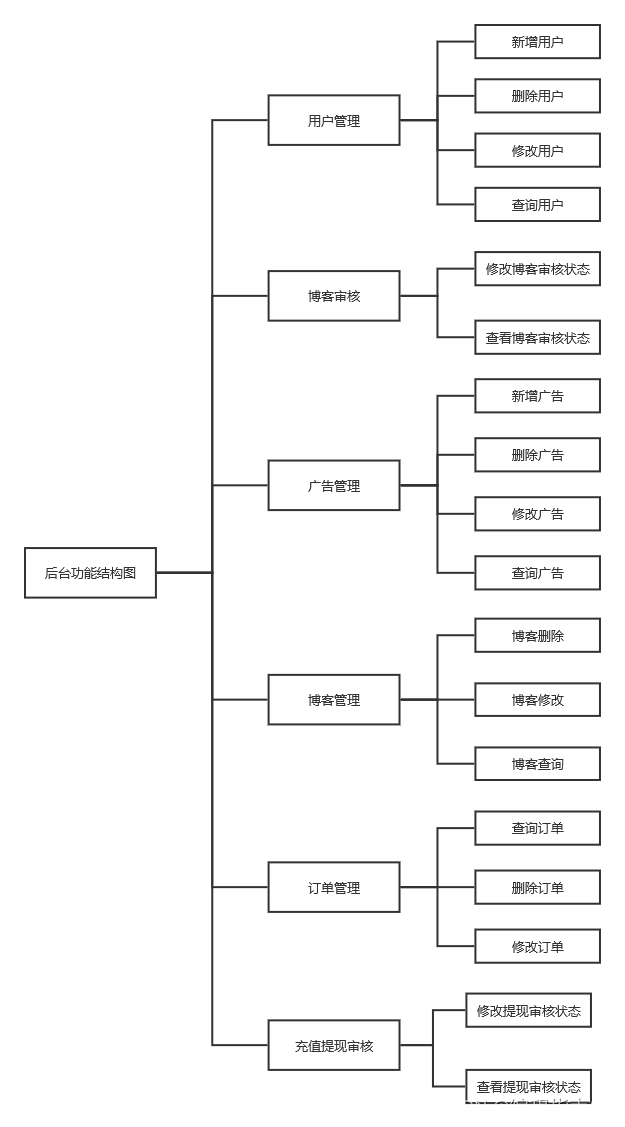
1.技术要求
(1)技术实施方案
博客系统采用了前后端分离的技术,前端我使用了vue框架,css,js,html等,使用的开发工具是WebStorm,缓存使用了redis,使用了RESP可视化工具。
后端我使用了SpringBoot快速开发脚手架,使用的开发工具是IDEA,数据库方面我用的是MySql,可视化工具采用的是Navicat。
前后端交互是前端使用Ajax进行跨域访问到后端的数据,得到数据后就返回到前端。
(2)系统测试方案
收集资料对IDEA开发工具,Java语言,Mysql数据库,vue框架进行深入学习和使用。根据系统分析对博客系统进行分类设计和详细设计。根据系统设计和详细设计对各功能进行系统实现。按规定对系统进行完整的测试,找出存在的问题,进一步完善博客系统。
2.工作要求
(1)技术可行性:
使用Vue+SpringBoot实现项目的前后端开发。Vue是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue被设计为可以自底向上逐层应用。Vue的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具链以及各种支持类库结合使用时,Vue也完全能够为复杂的单页应用提供驱动。Vue使用了双向数据绑定,即当数据发生变化的时候,视图也就发生变化,当视图发生变化的时候,数据也会跟着同步变化,这就是Vue的精髓所在。SpringBoot,在当前互联网后端开发中,JavaEE占据了主导地位。对JavaEE开发,首选框架是Spring框架。在传统的Spring开发中,需要使用大量的与业务无关的XML配置才能使Spring框架运行起来,这点备受许多开发者诟病。为了进一步简化Spring应用的开发,SpringBoot诞生了。其设计目的是为了进一步简化Spring应用的搭建及开发过程。Spring Boot 可以轻松创建独立的、生产级的基于 Spring 的应用程序,您可以“直接运行”这些应用程序。我们对 Spring 平台和第三方库采取了固执的观点,因此您可以轻松上手。大多数 Spring Boot 应用程序需要最少的 Spring 配置。所以技术是完全可行的。
三,系统展示
博客前台

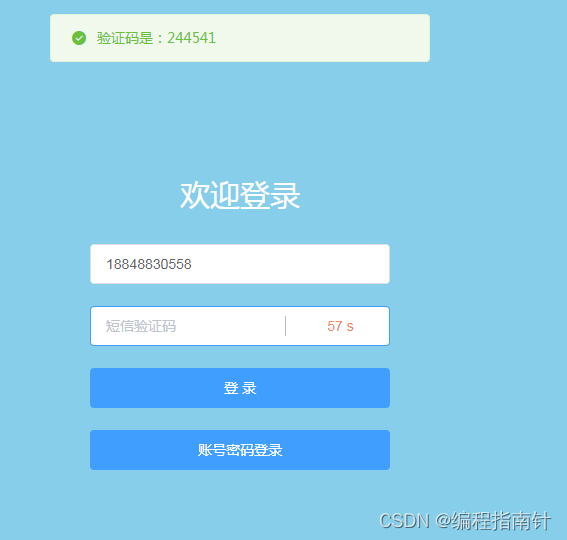
用户注册和登录


手机验证码登录:
本博客的特点是可以设置收费的博文和免费的博文,查看收费的博文需要从个人账户中扣费

个人中心中可以绑定自己的银行卡并进行在线充值和提现

提现

发布博文时可以选择收费或是免费的

博文分类浏览

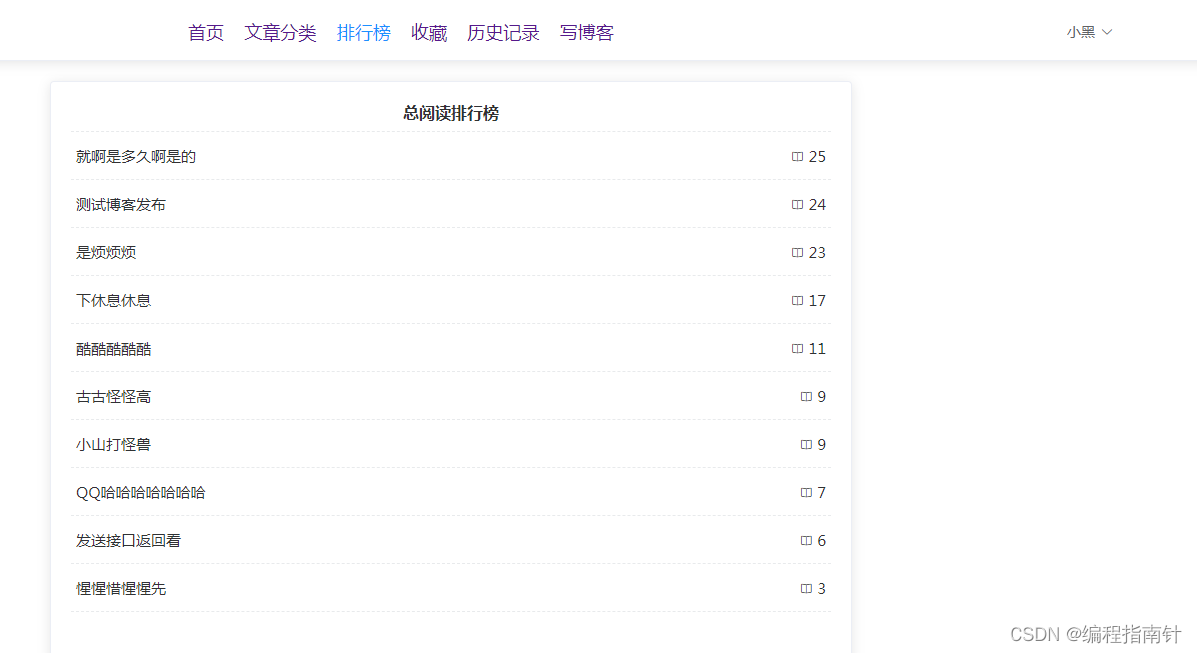
阅读排行榜
我的收藏

浏览记录
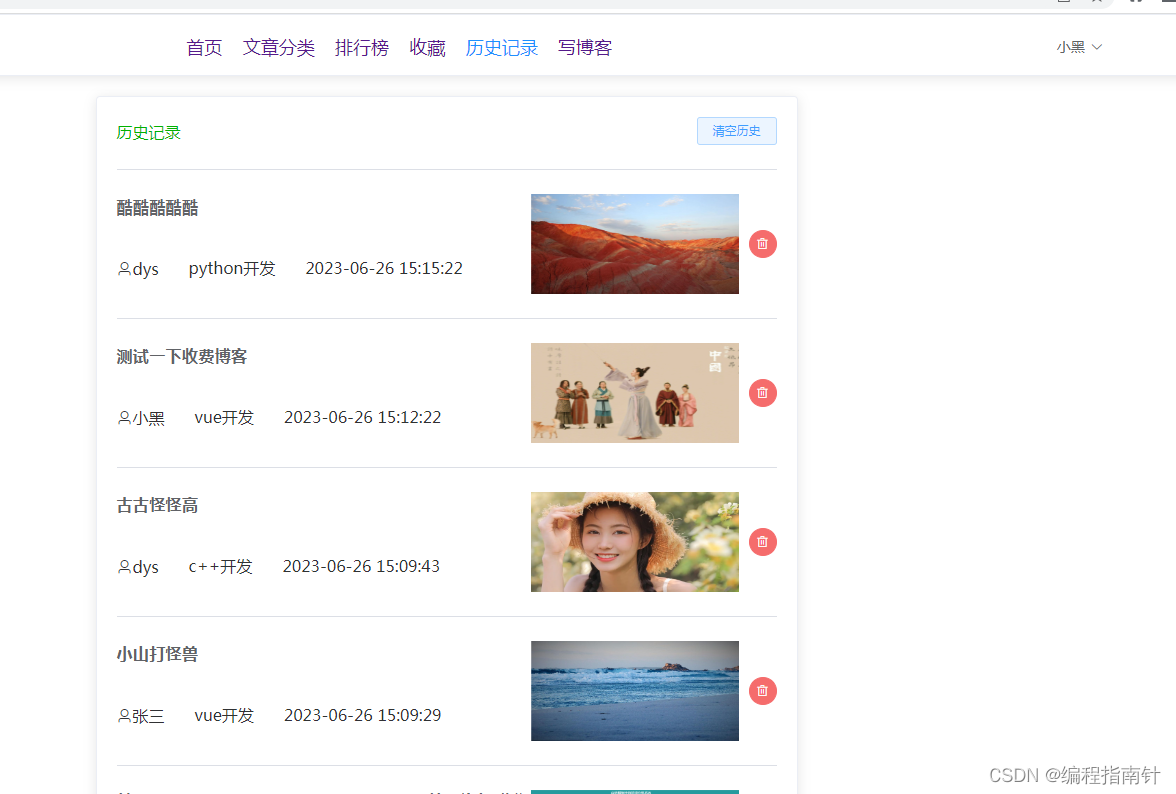
个人中心

后台登录

数据统计

用户管理

博客管理
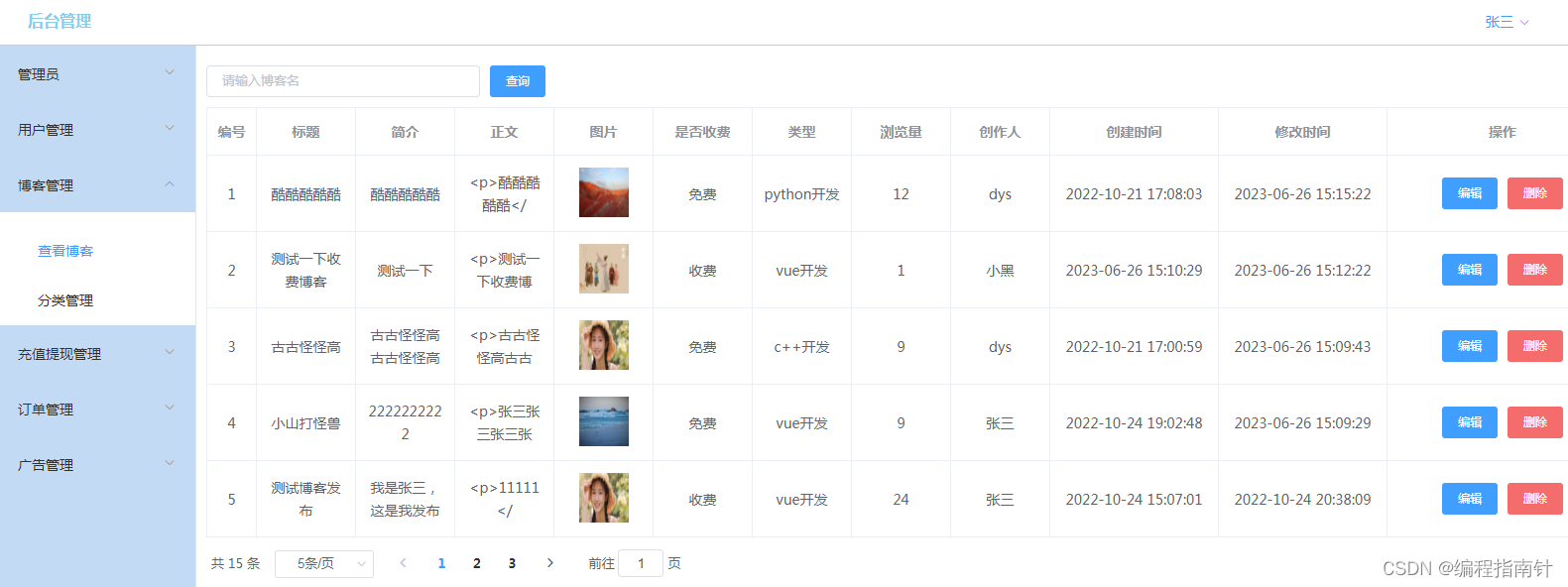
分类管理

充值记录

提现审核

订单管理
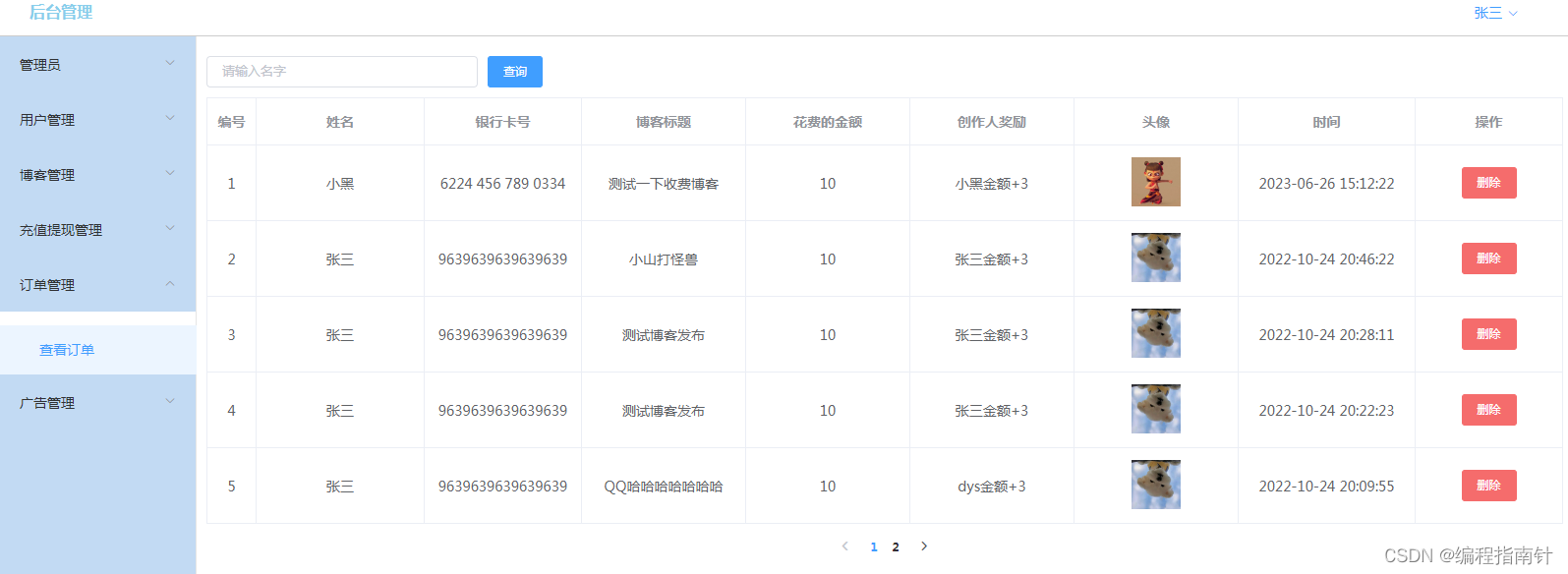
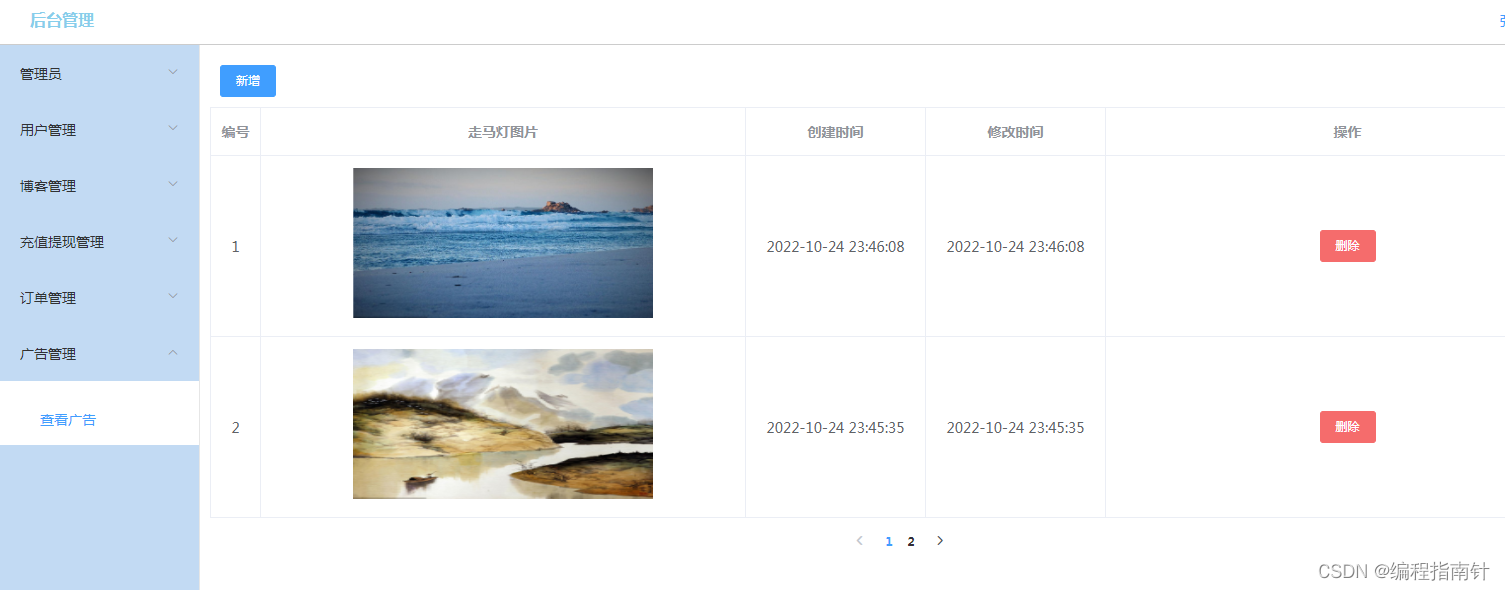
前端轮播广告图片管理
四,核心代码展示
package com.dys.controller;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.dys.R.R;
import com.dys.pojo.Classification;
import com.dys.pojo.Posts;
import com.dys.service.ClassificationService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/classification")
public class ClassificationController {
@Autowired
private ClassificationService classificationService;
/**
* 前端
* 查询所有的分类信息
* @return
*/
@PostMapping
public R getClassification(){
List<Classification> list = classificationService.list(null);
System.out.println("数据"+list);
return R.ok(list);
}
/**
* 条件分页查询,根据传来的条件去找到对应的数据
* @param page 分页
* @param search 条件
* @return R
*/
@GetMapping("/selectClassification")
public R selectClassification(Page<Classification> page,@RequestParam String search){
Page<Classification> classificationPage = classificationService.selectClassification(page, search);
return R.ok(classificationPage);
}
/**
* 新增分类
* @param classification 分类对象
* @return R
*/
@PostMapping("/addClassification")
public R addClassification(@RequestBody Classification classification){
boolean isOk = classificationService.addClassification(classification);
return isOk ? R.ok() : R.error();
}
/**
* 修改分类
* @param classification 分类对象
* @return R
*/
@PostMapping("/updateClassification")
public R updateClassification(@RequestBody Classification classification){
boolean isOk = classificationService.updateClassification(classification);
return isOk ? R.ok() : R.error();
}
/**
* 删除分类
* 注:删除分类的同时还要删除有这个分类对应的博客
* 在根据博客id删除收藏,历史记录,排行榜里面的对应的博客信息
* 在根据博客里面的用户id删除对应的创作博客信息
* @param id 分类ID
* @return R
*/
@DeleteMapping("/deleteClassification/{id}")
public R deleteClassification(@PathVariable String id){
boolean isOk = classificationService.deleteClassification(id);
return isOk ? R.ok() : R.error();
}
/**
* 后端
* 图表数据查询,先查询出所有的分类ID
* 在根据ID去博客表找对应的博客的数量
* 返回每个分类有多少个博客
* @return R
*/
@GetMapping("/selectEChartsData")
public R selectEChartsData(){
List<Classification> list = classificationService.selectEChartsData();
return R.ok(list);
}
}
package com.dys.controller;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.metadata.OrderItem;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.dys.R.R;
import com.dys.mapper.CollectionMapper;
import com.dys.pojo.Collection;
import com.dys.pojo.Posts;
import com.dys.service.CollectionService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/collection")
public class CollectionController {
@Autowired
private CollectionService collectionService;
/**
* 新增收藏记录
* @param collection
* @return
*/
@PostMapping("/addCollection")
public R addCollection(@RequestBody Collection collection){
//加上@RequestBody后可以接收前端传来的数据,把数据新增到数据库中
// boolean isOk = collectionService.saveCollection(collection);
//返回数据,当数据为真时返回成功,为假时返回失败
// return isOk ? R.ok() : R.error("已经收藏过了");
//TODO
collectionService.save(collection);
String id = collection.getId();
return R.ok(id);
}
/**
* 删除收藏记录
* @param id
* @return
*/
@DeleteMapping("/deleteCollection/{id}")
public R deleteCollection(@PathVariable String id){
// Collection collection = new Collection();
// collection.setUsersId(usersId);
// collection.setPostsId(postsId);
// boolean isOk = collectionService.deleteCollection(collection);
boolean isOk = collectionService.removeById(id);
return isOk ? R.ok() : R.error();
}
/**
* 查询是否收藏
* @param collection
* @return
*/
@PostMapping("/listCollection")
public R listCollection(@RequestBody Collection collection){
LambdaQueryWrapper<Collection> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Collection::getUsersId,collection.getUsersId()).eq(Collection::getPostsId,collection.getPostsId());
return R.ok(collectionService.getOne(wrapper));
}
/**
* 根据用户id查询所有已收藏的博客
* 上面是数据没分页,下面是将数据分页
* @param id
* @return
*/
// @PostMapping("/listAllCollection/{id}")
// public R listAllCollection(@PathVariable String id){
// return R.ok(collectionService.listAllCollection(id));
// }
@GetMapping("/listAllCollection/{id}")
public R listAllCollection(Page<Collection> page,@PathVariable String id){
page.addOrder(OrderItem.desc("create_time"));
return R.ok(collectionService.listAllCollection(page,id));
}
}
package com.dys.controller;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.metadata.OrderItem;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.dys.R.R;
import com.dys.pojo.Classification;
import com.dys.pojo.Posts;
import com.dys.pojo.dto.PostsDTO;
import com.dys.service.ClassificationService;
import com.dys.service.PostsService;
import com.dys.service.UsersService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.Comparator;
import java.util.List;
@RestController
@RequestMapping("/posts")
public class PostsController {
/**
* 博客表
*/
@Resource
private PostsService postsService;
/**
* 分类表
*/
@Autowired
private ClassificationService classificationService;
/**
* 用户表
*/
@Autowired
private UsersService usersService;
/**
* 后台
* 条件分页查询
* @param page 分页类,获取里面三个值:total:一共有多少个数据,size:每页可以存放的数据条数,current:当前是第几页
* @param search 搜索的关键字
* @return R
*/
@GetMapping("/postsPagingQuery")
public R postsPagingQuery(Page<Posts> page, @RequestParam String search){
// //mybatis-plus中的条件构造器,需要用到Lambda语法,使用Wrapper
// LambdaQueryWrapper<Posts> lambdaQueryWrapper = new LambdaQueryWrapper<>();
// //调用了like方法,实现模糊查询,lambda表达式查询条件,::获取实体类中的方法 ::--》Java8后:获取方法
// //StrUtil--》一个工具类,isNotEmpty和isNotBlank都是非空判断的方法(isNotBlank会排除空格,isNotEmpty不会排除空格)
if (search == null){
}
// lambdaQueryWrapper.like(StrUtil.isNotBlank(search),Posts::getTitle,search);
// //按照修改时间降序排列
// Page<Posts> postsPage = page.addOrder(OrderItem.desc("update_time"));
// //mybatis-plus好用自带的分页的方法,可以传两个参数(分页的起始位置,结束位置),接收前端传来的参数,查询的数量
// Page<Posts> servicePosts = postsService.page(postsPage, lambdaQueryWrapper);
//
// List<Posts> records = servicePosts.getRecords();
// records.forEach(item->{
// //TODO 填充typeName
// String typeName = classificationService.getTypeNameByTypeId(item.getClassificationId());
// String usersName = usersService.getUserNameByUsersId(item.getUsersId());
// item.setTypeName(typeName);
// item.setUsersName(usersName);
// });
// //返回数据
// return R.ok(servicePosts);
Page<Posts> postsPage = postsService.postsPagingQuery(page, search);
List<Posts> records = postsPage.getRecords();
records.forEach(item->{
//TODO 填充typeName
String typeName = classificationService.getTypeNameByTypeId(item.getClassificationId());
String usersName = usersService.getUserNameByUsersId(item.getUsersId());
item.setTypeName(typeName);
item.setUsersName(usersName);
});
return R.ok(postsPage);
}
/**
* 博客数据按浏览量排序
* @param posts
* @return
*/
@GetMapping("/getPostsAndViews")
public R getPostsAndViews(Posts posts){
// //按照浏览量降序排列
// Page<Posts> postsPage = page.addOrder(OrderItem.desc("views"));
// //mybatis-plus好用自带的分页的方法,可以传两个参数(分页的起始位置,结束位置),接收前端传来的参数,查询的数量
// Page<Posts> servicePosts = postsService.page(postsPage);
List<Posts> list = postsService.list();
//list.sort(Comparator.comparing(Posts::getViews).reversed()); .reversed() --》 根据条件进行降序排序
list.sort(Comparator.comparing(Posts::getViews).reversed());
//返回数据
return R.ok(list);
}
/**
* 查看博客详情,多表查询,根据用户id,类型id查询对应的名字
* @param id
* @return
*/
@GetMapping("/{id}/{isStatus}")
public R getPostsId(@PathVariable boolean isStatus,@PathVariable String id){
// Posts byId = postsService.getByIdWithTypeNameUsersName(id);
PostsDTO byId = postsService.getByIdWithTypeNameUsersName(isStatus,id);
return R.ok(byId);
}
/**
* 根据分类id查询对应的分类数据
* @param id
* @return
*/
@GetMapping("/classificationByIdData/{id}")
public R classificationByIdData(Page<Posts> page,@PathVariable String id){
// List<Posts> typeData = postsService.getByIdWithTypeData(page,id);
Page<PostsDTO> typeData = postsService.getByIdWithTypeData(page,id);
return R.ok(typeData);
}
/**
* 新增方法
* @param posts Posts实体类
* @return R
*/
@PostMapping
public R savePosts(@RequestBody Posts posts){
//加上@RequestBody后可以接收前端传来的数据,把数据新增到数据库中
boolean isOk = postsService.save(posts);
//返回数据,当数据为真时返回成功,为假时返回失败
return isOk ? R.ok() : R.error();
}
/**
* 修改方法
* @param posts Posts实体类
* @return R
*/
@PatchMapping("/updatePosts")
public R updatePosts(@RequestBody Posts posts){
boolean isOk = postsService.updateById(posts);
return isOk ? R.ok() : R.error();
}
/**
* 删除博客,删除博客的同时要删除历史记录中的博客和收藏的博客
* @param id Posts实体类
* @return R
*/
@DeleteMapping("/{id}")
public R deletePosts(@PathVariable String id){
boolean isOk = postsService.deletePosts(id);
return isOk ? R.ok() : R.error();
}
/**
* 前端
* 条件分页查询根据用户ID查找自己创作的博客
* @param id 用户ID
* @param postsPage 分页
* @param search 搜索条件
* @return R
*/
@GetMapping("/selectBlogById")
public R selectBlogById(Page<Posts> postsPage,@RequestParam String id,@RequestParam String search){
Page<Posts> page = postsService.selectBlogById(postsPage, id, search);
return R.ok(page);
}
}
五,项目总结
本项目开发实现了一个博客平台系统,相较于传统的博客系统来讲,它可以实现付费博文的功能,作者可以通过付费的知识型博文来进行收费获得一定的收益,这就像CSDN上可以发布收费的博客或专栏一样,希望本项目的实现能给大家一些参考思路。
智能推荐
MongoDB详解(有这一篇就够了)-程序员宅基地
文章浏览阅读4.1k次,点赞6次,收藏23次。MongoDB 是由C++语言编写的,基于分布式文件存储的数据库,是一个介于关系数据库和非关系数据库之间的产品,是最接近于关系型数据库的NoSQL数据库。MongoDB 旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于JSON对象。字段值可以包含其他文档,数组及文档数组类似于MongoDB优点:数据处理能力强,内存级数据库,查询速度快,扩展性强,只是不支持事务。_mongodb
两种内存池管理方法对比_非固定大小的内存池-程序员宅基地
文章浏览阅读1.9k次,点赞4次,收藏11次。目录一、问题背景二、两种内存池管理2.1 固定大小内存块分配(参考正点原子STM32F4 malloc.c)2.1.1 初始化2.1.3释放原理2.2 可变大小内存块分配(参考WSF BLE协议栈buffer management)2.2.1 初始化2.2.2 分配原理2.2.3 释放原理三、总结和对比一、问题背景最近在调试ambiq apollo..._非固定大小的内存池
MPEG TS流简介-程序员宅基地
文章浏览阅读3.1k次。TS简介MPEG-TS(Transport stream)即Mpeg传输流定义于ITU-T Rec. H.222.0和ISO 13818-1标准中,属于MPEG2的系统层。MPEG2-TS面向的传输介质是网络和卫星等可靠性较低的传输介质,这一点与面向较可靠介质如DVD等的MPEG PS不同。1. TS数据包TS流由TS数据包即Transport stream packet组成。TS p...
Deepin wine QQ/微信中文显示为方块的原因之一_wine 字体方块-程序员宅基地
文章浏览阅读984次。问题原因:目录下~/.deepinwine,查找乱码的应用Deepin-QQ、Deepin-WeChat,相同路径/drive_c/windows/Fonts下查看是否有字体,笔者发现没有任何字体,这就是原因所致,wine程序会在此处寻找字体,而不能直接利用linux系统的字体解决方法:把/usr/share/fonts/Fonts_Win下字体复制到这里,使wine应用程序能找到至少一种fallback字体,也可以在别的地方的fonts问价夹下,拷贝.ttf字体文件到这里..._wine 字体方块
整个元素周期表通用,AI 即时预测材料结构与特性-程序员宅基地
文章浏览阅读264次。编辑 | 绿萝材料的性质由其原子排列决定。然而,现有的获得这种排列的方法要么过于昂贵,要么对许多元素无效。现在,加州大学圣地亚哥分校纳米工程系的研究人员开发了一种人工智能算法,可以几乎即时地预测任何材料(无论是现有材料还是新材料)的结构和动态特性。该算法被称为 M3GNet,用于开发 matterverse.ai 数据库,该数据库包含超过 3100 万种尚未合成的材料,其特性由机器学习算法预测。M..._人工智能预测材料属性
Docker & Nvidia-docker 镜像基础操作_dokcer怎么使用nvidia作为基础镜像-程序员宅基地
文章浏览阅读5.8k次,点赞2次,收藏25次。简述 docker & nvidia-docker感觉是深度学习的环境配置与部署简化很多,下面记录一下基础的命令,为自己后续用到查阅。在使用之前请先安装好NVIDIA驱动,CUDA以及docker & nvidia-docker的基本环境。docker & nvidia-docker 导入与导出镜像导出镜像:nvidia-docker save -o /save_p..._dokcer怎么使用nvidia作为基础镜像
随便推点
dwd明细粒度事实层设计_dwd层如何设计-程序员宅基地
文章浏览阅读1.8k次。目录1-数仓dwd事实层介绍2-数仓dwd层事实表设计原则3-数仓dwd层事实表设计规范4-建表示例1-数仓dwd事实层介绍明细粒度事实层以业务过程驱动建模,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。您可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。公共汇总粒度事实层(DWS)和明细粒度事实层(DWD)的事实表作为数据仓库维度建模的核心,需紧绕业务过程来设计。通过获取描述业务过程的度量来描述业务过程,包括引用的维度和与业务过程有关的度量。度量通常为_dwd层如何设计
Ambari 2.7.3.0 安装部署 hadoop 3.1.0.0 集群视频完整版_ambari2.7.3 hadoop 部署-程序员宅基地
文章浏览阅读1.5k次。一、前言很多小伙伴也都知道,最近一直在做 Ambari 集成自定义服务的教学笔记和视频。之前在准备 Ambari 环境的时候,考虑到有朋友会在 Ambari 安装部署时遇到问题,所以贴心的我呢,就在搭建 Ambari 环境的时候,把这个视频录制好了,总共时长共 87 分钟,将近1个半小时,附带移除 SmartSense 服务及 FAQ 。也提前介绍一下搭建好的 Ambari 相关版本信息:..._ambari2.7.3 hadoop 部署
使用R语言保存CSV文件_r软件保存为csv文件-程序员宅基地
文章浏览阅读881次。本文介绍了如何使用R语言保存CSV文件。我们使用write.csv函数将数据框保存为CSV格式。您只需提供要保存的数据对象和文件路径,即可轻松创建CSV文件。CSV文件是一种通用的数据交换格式,在数据分析和数据处理中广泛使用。希望本文对您有所帮助,祝您在R语言中保存CSV文件时顺利进行数据处理和分析!_r软件保存为csv文件
VR技术赋能数字经济发展新机遇,加快构建双循环新发展格局_vr商城建设对区域经济-程序员宅基地
文章浏览阅读498次。当下,数字化浪潮正重塑世界经济发展格局,数字经济正在成为全球经济可持续增长新引擎。我国超大规模的市场经济优势为数字经济发展提供了广阔而丰富的应用场景,也成为推动传统产业升级改造、加快”构建国内国际双循环相互促进的新发展格局“的重要引擎。据国家统计局数据显示:2020年第一季度,我国GDP呈现出6.8%的负增长态势。今年1月份至5月份,与互联网相关的新业态、新模式却继续保持逆势增长。全国实物商品网上零售额同比增长11.5%;实物商品网上零售额占社会消费品零售总额比重为24.3%,比去年同期提高5.4个百分点_vr商城建设对区域经济
HCS12X–数据定义(如何在CodeWarrior中将数据定义到分页区)_codewarrior数组如何定义-程序员宅基地
文章浏览阅读384次。由于在暑假匆忙接收的嵌入式项目中需要使用特别大的数组,非分页RAM的内存不够用了,没办法,硬着头皮尝试使用分页RAM,但是完全没有单片机的基础,导致极其的困难。之前写程序都是按照纯软件的思维,主要考虑架构,不会考虑到每个变量具体存在哪个物理地址这么底层的问题,结果被飞思卡尔这分页地址、prm文件什么的搞得一头雾水,而网上的资料又少,讲的又大同小异的笼统,最后写出来的程序因为这分页地址的原因存在各种_codewarrior数组如何定义
wed服务器简介_wed服务器的主要特点之一就是它具有十几个html文件连接到另一个html文件的能力称为-程序员宅基地
摘要:Web服务器是用于提供Web服务的软件,它通过HTTP协议来传输和接收网页和其他资源。在Inteet上,HTTP通信通常在TCP/IP连接上进行,使用端口号80。Apache是一种常见的Web服务器软件,其主程序为httpd,根目录为/var/www/html。