Elasticsearch教程(9) Mapping 字段类型 keyword text date numeric_es mappings什么时候会把字段解析成text-程序员宅基地
技术标签: date mapping Elasticsearch elasticsearch 字段类型 keyword
Mapping 字段类型
前言
- 我们在用MySQL时,如果表结构定义不好,后期开发会不断踩坑。
- 用ES也是如此,虽然ES有mapping动态映射,但是它自动生成的不一定是我们期望的。学好ES的mapping很重要。在学习ES查询和聚合之前,应该先打好mapping的基础,学习顺序不能变。这和学习SQL一样,先学习数据类型有int,char,varchar等,然后再学习group by,having等。
核心字段类型
- ES支持的字段类型很多,但我们工作中常用的也就那些核心字段。
- 一开始学习ES时,掌握好常用的类型,不必要精通每一种,如果工作中遇到了需要用到特殊类型再去研究。
- 学习一门技术要先广度后深度,不能陷入”只见树木,不见森林“。
1 keyword
- keyword是关键词类型,ES把keyword类型的值当作词根存在倒排索引中,不进行分词。
- keyword适合存结构化数据,比如name,age,性别,手机号,status(数据状态),tags(标签),HttpCode(404,200,500)等。
- 字段常用来精确查询,过滤,排序,聚合时,应设为keyword,而不是数值型。
- 最长支持32766个UTF-8类型的字符,但放入倒排索引时,只截取前一段字符串,长度由ignore_above参数决定。
1.1 举例说明keyword
| 举例:数据状态字段 |
#如果一个字段经常用来放查询条件里过滤数据和聚合统计,
#最好设为keyword,而不是数值型
GET pigg/_search
{
"query": {
"term": {
"status": 2
}
}
}
1.2 ignore_above是什么?
首先随意往ES插一条数据:
put my_index/_doc/1
{
"name": "李星云"
}
查看ES自动生成的mapping,name是text类型,其下还有子类型keyword,且"ignore_above" : 256
GET /my_index/_mapping
name定义如下:
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
对于keyword类型, 可设置ignore_above限定字符长度。超过 ignore_above 的字符会被存储,但不会被倒排索引。比如ignore_above=4,”abc“,”abcd“,”abcde“都能存进ES,但是不能根据”abcde“检索到数据。
【1】创建一个keyword类型的字段,ignore_above=4
PUT test_index
{
"mappings": {
"_doc": {
"properties": {
"message": {
"type": "keyword",
"ignore_above": 4
}
}
}
}
}
【2】向索引插入3条数据:
PUT /test_index/_doc/1
{
"message": "abc"
}
PUT /test_index/_doc/2
{
"message": "abcd"
}
PUT /test_index/_doc/3
{
"message": "abcde"
}
此时ES倒排索引是:
| 词项 | 文档ID |
|---|---|
| abc | 1 |
| abcd | 2 |
【3】根据message进行terms聚合:
GET /test_index/_search
{
"size": 0,
"aggs": {
"term_message": {
"terms": {
"field": "message",
"size": 10
}
}
}
}
返回结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"message" : "abcd"
}
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"message" : "abc"
}
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"message" : "abcde"
}
}
]
},
"aggregations" : {
"term_message" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [#注意这分组里没有”abcde“
{
"key" : "abc",
"doc_count" : 1
},
{
"key" : "abcd",
"doc_count" : 1
}
]
}
}
}
【4】根据”abcde“进行term精确查询,结果为空
GET /test_index/_search
{
"query": {
"term": {
"message": "abcde"
}
}
}
然后结果:
"hits" : {
"total" : 0,
"max_score" : null,
"hits" : [ ]
}
通过上面结果能知道”abcde“已经存入ES,也可以搜索出来,但是不存在词项”abcde“,不能根据”abcde“作为词项进行检索。
对于已存在的keyword字段,其ignore_above子属性可以修改,但只对新数据有效。
2 text
- text文本类型,如果要对字符串进行分词分析,可以设置为text。
- ES自带了很多分词器,如果是中文,可以给ES安装ik中文分词插件。
- 关于分词器属性的配置可以参考ES官网分析的章节。
2.1 举例说明text类型分词
在上面1.1.2节,新增了my_index索引,其中name是text类型。
分析在name上”I am a coder“这个短语是怎么被分词的。
GET /my_index/_analyze
{
"field": "name",
"text": "I am a coder"
}
结果如下图,这短语分成4个词项,其中大写”I“还转换为小写”i“。
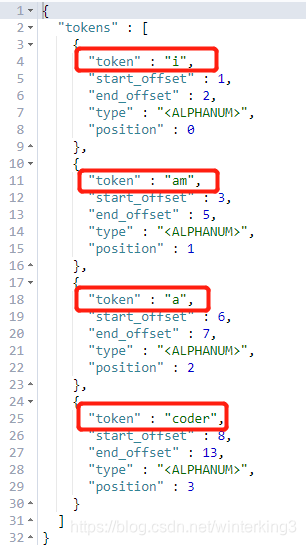
字符串”I am a coder“,ES不会把这个完整的字符串保存起来,它保存的形式如下:
| 词 | 假设文档ID=1 |
|---|---|
| i | 1 |
| am | 1 |
| a | 1 |
| coder | 1 |
所以根据”I am a coder“这完整字符串是查询不到数据的。
3 Boolean类型
| 判断 | ES接受的值 |
|---|---|
| 真 | true, “true” |
| 假 | false, “false”,""(空字符串) |
具体代码案例参考Elasticsearch笔记(二十三) 详解mapping之boolean
4 日期类型
JSON没有date数据类型,所以ES里日期可有以下数据:
- 日期格式的字符串,如"2015-01-01"或"2015/01/01 12:10:30"
- 从开始纪元(1970-01-01 00:00:00 UTC)开始的毫秒数-长整型
- 从开始纪元(1970-01-01 00:00:00 UTC)开始的秒数-整型
上面的UTC(Universal Time Coordinated) 叫做世界统一时间,中国大陆和 UTC 的时差是 + 8 ,也就是 UTC+8。在ES内部,时间以毫秒数的UTC存储。
date的格式可以被指定的,如果没有特殊指定,默认格式是"strict_date_optional_time||epoch_millis"
这段话可以理解为格式为strict_date_optional_time或者epoch_millis
4.1 什么是epoch_millis?
epoch_millis就是从开始纪元(1970-01-01 00:00:00 UTC)开始的毫秒数-长整型。
4.2 什么是strict_date_optional_time?
strict_date_optional_time是date_optional_time的严格级别,这个严格指的是年份、月份、天必须分别以4位、2位、2位表示,不足两位的话第一位需用0补齐。
常见的格式有如下:
- yyyy
- yyyyMM
- yyyyMMdd
- yyyyMMddHHmmss
- yyyy-MM
- yyyy-MM-dd
- yyyy-MM-ddTHH:mm:ss
- yyyy-MM-ddTHH:mm:ss.SSS
- yyyy-MM-ddTHH:mm:ss.SSSZ
工作常见到是"yyyy-MM-dd HH:mm:ss",但是ES是不支持这格式的,需要在dd后面加个T,这个是固定格式。上面最后一个里大写的"Z"表示时区。
下面做测试:
#新增一个索引,设置birthday是date格式。
PUT /test_date_index
{
"mappings": {
"_doc":{
"properties":{
"birthday":{
"type": "date"
}
}
}
}
}
#插入yyyy-MM-dd HH:mm:ss格式
PUT /test_date_index/_doc/3
{
"birthday": "2020-03-01 16:29:41"
}
结果报错:
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Invalid format: \"2020-03-01 16:29:41\" is malformed at \" 16:29:41\""
}
#插入 yyyy-MM-ddTHH:mm:ss格式,ES返回成功
PUT /test_date_index/_doc/4
{
"birthday": "2020-03-01T16:29:41"
}
4.3 你就是想用yyyy-MM-dd HH:mm:ss?
date类型,还支持一个参数format,它让我们可以自己定制化日期格式。
比如format配置了“格式A||格式B||格式C”,插入一个值后,会从左往右匹配,直到有一个格式匹配上。
#先删除索引
DELETE test_date_index
#重建索引
PUT /test_date_index
{
"mappings": {
"_doc":{
"properties":{
"birthday":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
#2020/03/01 17:44:09的毫秒级时间戳
PUT /test_date_index/_doc/1
{
"birthday": 1583055849000
}
PUT /test_date_index/_doc/2
{
"birthday": "2020-03-01 16:29:41"
}
PUT /test_date_index/_doc/3
{
"birthday": "2020-02-29"
}
#上面3条语句都可以保存成功
5 数字:Numeric
为了提高性能和减少存储空间,选择一个满足存放你数据的类型就可以,没有必要选择过长的类型。比如各地人口数量,一般用integer存储足够了,没有必要使用long类型。
| 类型 | 说明 |
|---|---|
| byte | 8位,-128 ~ 127 |
| short | 16位,-32768 ~ 32767 |
| integer | 32位,-231 ~ 231-1 |
| long | 64位,-263 ~ 263-1 |
| float | 单精度、32位、符合IEEE 754标准的浮点数 |
| double | 双精度、64位、符合IEEE 754标准的浮点数 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数 |
5.1 创建一个新的索引
PUT pigg_test_num
{
"mappings": {
"properties": {
"num_of_byte": {
"type": "byte"
},
"num_of_short": {
"type": "short"
},
"num_of_integer": {
"type": "integer"
},
"num_of_long": {
"type": "long"
},
"num_of_float": {
"type": "float"
},
"num_of_double": {
"type": "double"
}
}
}
}
5.2 插入正确的数据
PUT pigg_test_num/_doc/1
{
"num_of_byte": 127,
"num_of_short": 32767,
"num_of_integer": 2147483647,
"num_of_long": 9223372036854775807,
"num_of_float": 0.33333,
"num_of_double": 11111111111111.11111111111111111
}
查看文档的数据
GET pigg_test_num/_search
返回:
{
"hits":[
{
"_index":"pigg_test_num",
"_type":"_doc",
"_id":"1",
"_score":1,
"_source":{
"num_of_byte":127,
"num_of_short":32767,
"num_of_integer":2147483647,
"num_of_long":9223372036854776000,
"num_of_float":0.33333,
"num_of_double":11111111111111.111
}
}
]
}
5.3 插入越界的数据
short的最大值是32767
PUT pigg_test_num/_doc/2
{
"num_of_byte": 127,
"num_of_short": 32768
}
返回报错
"reason" : "Numeric value (32768) out of range of Java short..."
5.4 给整数赋值浮点数
给long类型赋值浮点数, 虽然能够存储成功,但是已经丢失了精度,所以工作中不能这么用
PUT pigg_test_num/_doc/1
{
"num_of_long": 9223372036854775807.0001
}
返回
"_source" : {
"num_of_long" : 9.223372036854776E18
}
5.5 给整数赋值浮点数的字符串
给long类型赋值浮点数, 虽然能够存储成功, 但是存的就是字符串,而不是数字.
PUT pigg_test_num/_doc/1
{
"num_of_long": "9223372036854775807.0001"
}
返回
"_source" : {
"num_of_long" : "9223372036854775807.0001"
}
下面验证存的是字符串而不是数字
#期望给long的值加上2
POST pigg_test_num/_update/1
{
"script": {
"source": "ctx._source.num_of_long += 2",
"lang": "painless"
}
}
# 返回值却是给字符串拼接加上字符"2"
"_source" : {
"num_of_long" : "9223372036854775807.00012"
}
总结: 综合上面错误的实验, 可以知道工作中还是得传正确格式和范围的数字.
6 二进制类型:binary
ES能接受以Base64编码的二进制值,binary字段是不会被分析存储和检索的。因为它的值就是一巨长的乱码,对它分析毫无意义, 它只是被原模原样的存储。
工作中可能用binary存储图像,但情况也不多,用ES存图像不是很好的选择。
Base64编码简单说下,如下图:对单词"Man",它Base64编码是TWFu。

智能推荐
hive使用适用场景_大数据入门:Hive应用场景-程序员宅基地
文章浏览阅读5.8k次。在大数据的发展当中,大数据技术生态的组件,也在不断地拓展开来,而其中的Hive组件,作为Hadoop的数据仓库工具,可以实现对Hadoop集群当中的大规模数据进行相应的数据处理。今天我们的大数据入门分享,就主要来讲讲,Hive应用场景。关于Hive,首先需要明确的一点就是,Hive并非数据库,Hive所提供的数据存储、查询和分析功能,本质上来说,并非传统数据库所提供的存储、查询、分析功能。Hive..._hive应用场景
zblog采集-织梦全自动采集插件-织梦免费采集插件_zblog 网页采集插件-程序员宅基地
文章浏览阅读496次。Zblog是由Zblog开发团队开发的一款小巧而强大的基于Asp和PHP平台的开源程序,但是插件市场上的Zblog采集插件,没有一款能打的,要么就是没有SEO文章内容处理,要么就是功能单一。很少有适合SEO站长的Zblog采集。人们都知道Zblog采集接口都是对Zblog采集不熟悉的人做的,很多人采取模拟登陆的方法进行发布文章,也有很多人直接操作数据库发布文章,然而这些都或多或少的产生各种问题,发布速度慢、文章内容未经严格过滤,导致安全性问题、不能发Tag、不能自动创建分类等。但是使用Zblog采._zblog 网页采集插件
Flink学习四:提交Flink运行job_flink定时运行job-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏2次。restUI页面提交1.1 添加上传jar包1.2 提交任务job1.3 查看提交的任务2. 命令行提交./flink-1.9.3/bin/flink run -c com.qu.wc.StreamWordCount -p 2 FlinkTutorial-1.0-SNAPSHOT.jar3. 命令行查看正在运行的job./flink-1.9.3/bin/flink list4. 命令行查看所有job./flink-1.9.3/bin/flink list --all._flink定时运行job
STM32-LED闪烁项目总结_嵌入式stm32闪烁led实验总结-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。这个项目是基于STM32的LED闪烁项目,主要目的是让学习者熟悉STM32的基本操作和编程方法。在这个项目中,我们将使用STM32作为控制器,通过对GPIO口的控制实现LED灯的闪烁。这个STM32 LED闪烁的项目是一个非常简单的入门项目,但它可以帮助学习者熟悉STM32的编程方法和GPIO口的使用。在这个项目中,我们通过对GPIO口的控制实现了LED灯的闪烁。LED闪烁是STM32入门课程的基础操作之一,它旨在教学生如何使用STM32开发板控制LED灯的闪烁。_嵌入式stm32闪烁led实验总结
Debezium安装部署和将服务托管到systemctl-程序员宅基地
文章浏览阅读63次。本文介绍了安装和部署Debezium的详细步骤,并演示了如何将Debezium服务托管到systemctl以进行方便的管理。本文将详细介绍如何安装和部署Debezium,并将其服务托管到systemctl。解压缩后,将得到一个名为"debezium"的目录,其中包含Debezium的二进制文件和其他必要的资源。注意替换"ExecStart"中的"/path/to/debezium"为实际的Debezium目录路径。接下来,需要下载Debezium的压缩包,并将其解压到所需的目录。
Android 控制屏幕唤醒常亮或熄灭_android实现拿起手机亮屏-程序员宅基地
文章浏览阅读4.4k次。需求:在诗词曲文项目中,诗词整篇朗读的时候,文章没有读完会因为屏幕熄灭停止朗读。要求:在文章没有朗读完毕之前屏幕常亮,读完以后屏幕常亮关闭;1.权限配置:设置电源管理的权限。
随便推点
目标检测简介-程序员宅基地
文章浏览阅读2.3k次。目标检测简介、评估标准、经典算法_目标检测
记SQL server安装后无法连接127.0.0.1解决方法_sqlserver 127 0 01 无法连接-程序员宅基地
文章浏览阅读6.3k次,点赞4次,收藏9次。实训时需要安装SQL server2008 R所以我上网上找了一个.exe 的安装包链接:https://pan.baidu.com/s/1_FkhB8XJy3Js_rFADhdtmA提取码:ztki注:解压后1.04G安装时Microsoft需下载.NET,更新安装后会自动安装如下:点击第一个傻瓜式安装,唯一注意的是在修改路径的时候如下不可修改:到安装实例的时候就可以修改啦数据..._sqlserver 127 0 01 无法连接
js 获取对象的所有key值,用来遍历_js 遍历对象的key-程序员宅基地
文章浏览阅读7.4k次。1. Object.keys(item); 获取到了key之后就可以遍历的时候直接使用这个进行遍历所有的key跟valuevar infoItem={ name:'xiaowu', age:'18',}//的出来的keys就是[name,age]var keys=Object.keys(infoItem);2. 通常用于以下实力中 <div *ngFor="let item of keys"> <div>{{item}}.._js 遍历对象的key
粒子群算法(PSO)求解路径规划_粒子群算法路径规划-程序员宅基地
文章浏览阅读2.2w次,点赞51次,收藏310次。粒子群算法求解路径规划路径规划问题描述 给定环境信息,如果该环境内有障碍物,寻求起始点到目标点的最短路径, 并且路径不能与障碍物相交,如图 1.1.1 所示。1.2 粒子群算法求解1.2.1 求解思路 粒子群优化算法(PSO),粒子群中的每一个粒子都代表一个问题的可能解, 通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。 在路径规划中,我们将每一条路径规划为一个粒子,每个粒子群群有 n 个粒 子,即有 n 条路径,同时,每个粒子又有 m 个染色体,即中间过渡点的_粒子群算法路径规划
量化评价:稳健的业绩评价指标_rar 海龟-程序员宅基地
文章浏览阅读353次。所谓稳健的评估指标,是指在评估的过程中数据的轻微变化并不会显著的影响一个统计指标。而不稳健的评估指标则相反,在对交易系统进行回测时,参数值的轻微变化会带来不稳健指标的大幅变化。对于不稳健的评估指标,任何对数据有影响的因素都会对测试结果产生过大的影响,这很容易导致数据过拟合。_rar 海龟
IAP在ARM Cortex-M3微控制器实现原理_value line devices connectivity line devices-程序员宅基地
文章浏览阅读607次,点赞2次,收藏7次。–基于STM32F103ZET6的UART通讯实现一、什么是IAP,为什么要IAPIAP即为In Application Programming(在应用中编程),一般情况下,以STM32F10x系列芯片为主控制器的设备在出厂时就已经使用J-Link仿真器将应用代码烧录了,如果在设备使用过程中需要进行应用代码的更换、升级等操作的话,则可能需要将设备返回原厂并拆解出来再使用J-Link重新烧录代码,这就增加了很多不必要的麻烦。站在用户的角度来说,就是能让用户自己来更换设备里边的代码程序而厂家这边只需要提供给_value line devices connectivity line devices