
”爬虫“ 的搜索结果
python链家数据爬虫,内含源代码和详细的文档说明,欢迎学习。

结论: 在本篇博客中,我们介绍了五个实用的Python爬虫案例,并提供了相应的代码示例和解析。这些案例涵盖了不同的应用场景,包括爬取天气数据、图片下载、电影评论、新闻文章爬取和文本分析,以及股票数据爬取和...
Python是一种非常适合用于编写网络爬虫的编程语言。以下是一些Python爬虫的基本步骤:
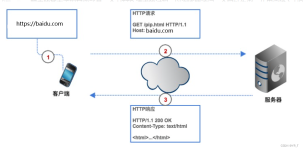
早在1989年,网络发明人蒂姆·伯纳斯 - 李(Tim Berners-Lee)就提出了网站的三大支柱:1)URL ,跟踪Web文档的地址系统2)HTTP,一个传输协议,以便在给定URL时查找文档3)HTML, 允许嵌入超链接的文档格式Web的最初...
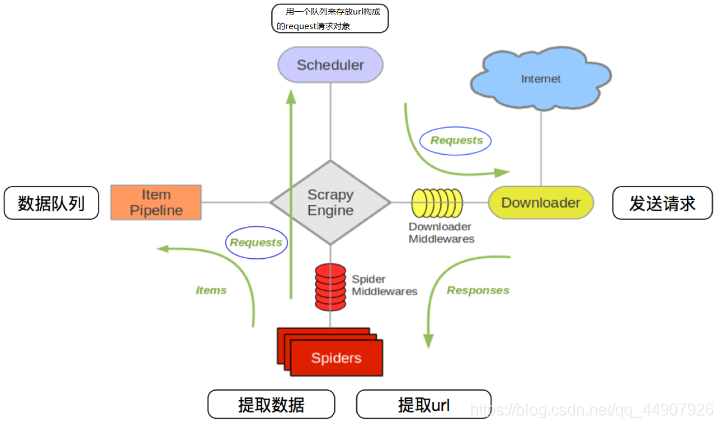
Python爬虫是一种使用Python编程语言实现的自动化获取网页数据的技术。它广泛应用于数据采集、数据分析、网络监测等领域。以下是对Python爬虫的详细介绍: 1. **架构和组成**: - **下载器**:负责根据指定的URL...
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了
爬虫,又名“网络爬虫”,就是能够自动访问互联网并将网站内容下载下来的程序。它也是搜索引擎的基础,像百度和GOOGLE都是凭借强大的网络爬虫,来检索海量的互联网信息的然后存储到云端,为网友提供优质的搜索服务的...

爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序。从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到...
包含了所有的源代码,本项目是一个练手的爬虫小案例。
81个Python爬虫源代码+九款开源爬虫工具,81个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
python爬虫,并将数据进行可视化分析,数据可视化包含饼图、柱状图、漏斗图、词云、另附源代码和报告书。
跟着路飞学城樵夫老师一点点敲的,都能跑通,后面的爬取数据添加到excel和mysql数据库是看的另外老师的视频
多年爬虫领域老工程师深度总结反爬虫技术原理与场景,带你快速了解并掌握反爬虫技术栈知识
这是一份同学的爬虫的毕业论文,完整的。需要的赶紧拿走
81个Python爬虫源代码
标签: 爬虫
81个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源

模板爬虫的主要优势在于简化了爬虫的开发过程!降低了技术门槛,提高了爬虫的可维护性和灵活性
讲诉python爬虫的20个案例 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。

闲鱼爬虫,可以爬取商品
标签: 爬虫
非常简单的一个闲鱼爬虫,可以爬取自己要求的价格区间的商品
爬虫和池是爬虫领域中不可或缺的概念,池能够提高爬虫的稳定性和效率,同时帮助爬虫更好地适应目标的反爬虫策略。
该资源为完整版的python代码,python2.7.实现简单的网络爬虫,爬去目标数据
推荐文章
- 『Android 技能篇』优雅的转场动画之 Transition-程序员宅基地
- Webshell绕过技巧分析之-base64编码和压缩编码-程序员宅基地
- 大一计算机思维知识点,大学计算机—基于计算思维知识点详解.docx-程序员宅基地
- 关于敏捷开发的一篇访谈录-程序员宅基地
- 挑战安卓和iOS!刚刚,华为官宣鸿蒙手机版,P40搭载演示曝光!高管现场表态:我们准备好了...-程序员宅基地
- 精选了20个Python实战项目(附源码),拿走就用!-程序员宅基地
- android在线图标生成工具,图标在线生成工具Android Asset Studio的使用-程序员宅基地
- android 无限轮播的广告位_轮播广告位-程序员宅基地
- echart省会流向图(物流运输、地图)_java+echart地图+物流跟踪-程序员宅基地
- Ceph源码解析:读写流程_ceph 发送数据到其他副本的源码-程序员宅基地